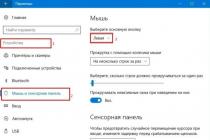
Целью курсовой работы является изучение технологии OLAP, понятие ее реализации и структуры.
В современном мире компьютерные сети и вычислительные системы позволяют анализировать и обрабатывать большие массивы данных.
Большой объем информации сильно усложняет поиск решений, но дает возможность получить намного точнее расчеты и анализ. Для решения такой проблемы существует целый класс информационных систем, выполняющих анализ. Такие системы называют системами поддержки принятия решений (СППР) (DSS, Decision Support System).
Для выполнения анализа СППР должна накапливать информацию, обладая средствами ее ввода и хранения. Всего можно выделить три основные задачи, решаемые в СППР:
· ввод данных;
· хранение данных;
· анализ данных.
Ввод данных в СППР осуществляется автоматически от датчиков, характеризующих состояние среды или процесса, или человеком-оператором.
Если ввод данных осуществляется автоматически от датчиков, то данные накапливаются по сигналу готовности, возникающему при появлении информации или путем циклического опроса. Если же ввод осуществляется человеком, то они должны предоставлять пользователям удобные средства для ввода данных, проверяющих их на правильность ввода, а так же выполнять необходимые вычисления.
При вводе данных одновременно несколькими операторами, необходимо решать проблемы модификации и параллельного доступа одних и тех же данных.
СППР предоставляет аналитику данные в виде отчетов, таблиц, графиков для изучения и анализа, именно поэтому такие системы обеспечивают выполнение функции поддержки принятия решений.
В подсистемах ввода данных, называемых OLTP (On-linetransactionprocessing), реализуется операционная обработка данных. Для их реализации используют обычные системы управления БД (СУБД).
Подсистема анализа может быть построена на основе:
· подсистемы информационно-поискового анализа на базе реляционных СУБД и статических запросов с использованием языка SQL;
· подсистемы оперативного анализа. Для реализации таких подсистем применяется технология оперативной аналитической обработки данных OLAP, использующая концепцию многомерного представления данных;
· подсистемы интеллектуального анализа. Данная подсистема реализует методы и алгоритмы DataMining .
С точки зрения пользователя, OLAP-системы представляют средства гибкого просмотра информации в различных срезах, автоматического получения агрегированных данных, выполнения аналитических операций свёртки, детализации, сравнения во времени. Благодаря всему этому OLAP-системы являются решением с большими преимуществами в области подготовки данных для всех видов бизнес-отчетности, предполагающих представление данных в различных разрезах и разных уровнях иерархии, таких как, отчетов по продажам, различных форм бюджетов и других. OLAP-системы имеет большие плюсы подобного представления и в других формах анализа данных, в том числе для прогнозирования.
1.2 Определение OLAP -систем
Технология комплексного многомерного анализа данных получила название OLAP. OLAP - это ключевой компонент организации ХД.
OLAP-функциональность может быть реализована различными способами, как простейшими, такими как анализ данных в офисных приложениях, так и более сложными - распределенными аналитическими системами, основанными на серверных продуктах.
OLAP (On-LineAnalyticalProcessing) – технология оперативной аналитической обработки данных использующая средства и методы для сбора, хранения и анализа многомерных данных и целях поддержки процессов принятия решений.
Основное назначение OLAP-систем - поддержка аналитической деятельности, произвольных запросов пользователей-аналитиков. Целью OLAP-анализа является проверка возникающих гипотез.
Условия высокой конкуренции и растущей динамики внешней среды диктуют повышенные требования к системам управления предприятия. Развитие теории и практики управления сопровождались появлением новых методов, технологий и моделей, ориентированных на повышение эффективности деятельности. Методы и модели в свою очередь способствовали появлению аналитических систем. Востребованность аналитических систем в России – высокая. Наиболее интересны с точки зрения применения эти системы в финансовой сфере: банки, страховой бизнес, инвестиционные компании. Результаты работы аналитических систем необходимы в первую очередь людям, от решения которых зависит развитие компании: руководителям, экспертам, аналитикам. Аналитические системы позволяют решать задачи консолидации, отчетности, оптимизации и прогнозирования. До настоящего времени не сложилось окончательной классификации аналитических систем, как и нет общей системы определений в терминах, использующихся в данном направлении. Информационная структура предприятия может быть представлена последовательностью уровней, каждый из которых характеризуется своим способом обработки и управления информацией, и имеет свою функцию в процессе управления. Таким образом аналитические системы будут располагаться иерархически на разных уровнях этой инфраструктуры.
Уровень транзакционных систем
Уровень хранилищ данных
Уровень витрин данных
Уровень OLAP – систем
Уровень аналитических приложений
OLAP - системы - (OnLine Analytical Processing, аналитическая обработка в настоящем времени) - представляют собой технологию комплексного многомерного анализа данных. OLAP - системы применимы там, где есть задача анализа многофакторных данных. Являют собой эффективное средство анализа и генерации отчетов. Рассмотренные выше хранилища данных, витрины данных и OLAP - системы относятся к системам бизнес - интеллекта (Business Intelligence, BI).
Очень часто информационно-аналитические системы, создаваемые в расчете на непосредственное использование лицами, принимающими решения, оказываются чрезвычайно просты в применении, но жестко ограничены в функциональности. Такие статические системы называются в литературе Информационными системами руководителя (ИСР), или Executive Information Systems (EIS) . Они содержат в себе предопределенные множества запросов и, будучи достаточными для повседневного обзора, неспособны ответить на все вопросы к имеющимся данным, которые могут возникнуть при принятии решений. Результатом работы такой системы, как правило, являются многостраничные отчеты, после тщательного изучения которых у аналитика появляется новая серия вопросов. Однако каждый новый запрос, непредусмотренный при проектировании такой системы, должен быть сначала формально описан, закодирован программистом и только затем выполнен. Время ожидания в таком случае может составлять часы и дни, что не всегда приемлемо. Таким образом, внешняя простота статических СППР, за которую активно борется большинство заказчиков информационно-аналитических систем, оборачивается катастрофической потерей гибкости.
Динамические СППР, напротив, ориентированы на обработку нерегламентированных (ad hoc) запросов аналитиков к данным. Наиболее глубоко требования к таким системам рассмотрел E. F. Codd в статье , положившей начало концепции OLAP. Работа аналитиков с этими системами заключается в интерактивной последовательности формирования запросов и изучения их результатов.
Но динамические СППР могут действовать не только в области оперативной аналитической обработки (OLAP); поддержка принятия управленческих решений на основе накопленных данных может выполняться в трех базовых сферах .
Сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации. В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом языка манипулирования реляционными данными является SQL. Информационно-поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации, могут использоваться в качестве надстроек как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных.
Сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация, гиперкубическое представление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLAP) . Здесь можно или ориентироваться на специальные многомерные СУБД , или оставаться в рамках реляционных технологий. Во втором случае заранее агрегированные данные могут собираться в БД звездообразного вида, либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной БД.
Сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining) , главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов.
Оперативная аналитическая обработка данных
В основе концепции OLAP лежит принцип многомерного представления данных. В 1993 году в статье E. F. Codd рассмотрел недостатки реляционной модели, в первую очередь указав на невозможность "объединять, просматривать и анализировать данные с точки зрения множественности измерений, то есть самым понятным для корпоративных аналитиков способом", и определил общие требования к системам OLAP, расширяющим функциональность реляционных СУБД и включающим многомерный анализ как одну из своих характеристик.
Классификация продуктов OLAP по способу представления данных.
В настоящее время на рынке присутствует большое количество продуктов, которые в той или иной степени обеспечивают функциональность OLAP. Около 30 наиболее известных перечислены в списке обзорного Web-сервера http://www.olapreport.com/. Обеспечивая многомерное концептуальное представление со стороны пользовательского интерфейса к исходной базе данных, все продукты OLAP делятся на три класса по типу исходной БД.
Самые первые системы оперативной аналитической обработки (например, Essbase компании Arbor Software , Oracle Express Server компании Oracle ) относились к классу MOLAP, то есть могли работать только со своими собственными многомерными базами данных. Они основываются на патентованных технологиях для многомерных СУБД и являются наиболее дорогими. Эти системы обеспечивают полный цикл OLAP-обработки. Они либо включают в себя, помимо серверного компонента, собственный интегрированный клиентский интерфейс, либо используют для связи с пользователем внешние программы работы с электронными таблицами. Для обслуживания таких систем требуется специальный штат сотрудников, занимающихся установкой, сопровождением системы, формированием представлений данных для конечных пользователей.
Системы оперативной аналитической обработки реляционных данных (ROLAP) позволяют представлять данные, хранимые в реляционной базе, в многомерной форме , обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных. ROLAP-системы хорошо приспособлены для работы с крупными хранилищами. Подобно системам MOLAP, они требуют значительных затрат на обслуживание специалистами по информационным технологиям и предусматривают многопользовательский режим работы.
Наконец, гибридные системы (Hybrid OLAP, HOLAP) разработаны с целью совмещения достоинств и минимизации недостатков, присущих предыдущим классам. К этому классу относится Media/MR компании Speedware . По утверждению разработчиков, он объединяет аналитическую гибкость и скорость ответа MOLAP с постоянным доступом к реальным данным, свойственным ROLAP.
Многомерный OLAP (MOLAP)
В специализированных СУБД, основанных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов:
1) гиперкубов (все хранимые в БД ячейки должны иметь одинаковую мерность, то есть находиться в максимально полном базисе измерений) или
2) поликубов (каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы).
Использование многомерных БД в системах оперативной аналитической обработки имеет следующие достоинства.
В случае использования многомерных СУБД поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных, так как многомерная база данных денормализована, содержит заранее агрегированные показатели и обеспечивает оптимизированный доступ к запрашиваемым ячейкам.
Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным.
С другой стороны, имеются существенные ограничения.
Многомерные СУБД не позволяют работать с большими базами данных. К тому же за счет денормализации и предварительно выполненной агрегации объем данных в многомерной базе, как правило, соответствует (по оценке Кодда ) в 2.5-100 раз меньшему объему исходных детализированных данных.
Многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память. В подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения удаётся удалить только за счет выбора оптимального порядка сортировки, позволяющего организовать данные в максимально большие непрерывные группы. Но даже в этом случае проблема решается только частично. Кроме того, оптимальный с точки зрения хранения разреженных данных порядок сортировки скорее всего не будет совпадать с порядком, который чаще всего используется в запросах. Поэтому в реальных системах приходится искать компромисс между быстродействием и избыточностью дискового пространства, занятого базой данных.
Следовательно, использование многомерных СУБД оправдано только при следующих условиях.
Объем исходных данных для анализа не слишком велик (не более нескольких гигабайт), то есть уровень агрегации данных достаточно высок.
Набор информационных измерений стабилен (поскольку любое изменение в их структуре почти всегда требует полной перестройки гиперкуба).
Время ответа системы на нерегламентированные запросы является наиболее критичным параметром.
Требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций.
Реляционный OLAP (ROLAP)
Непосредственное использование реляционных БД в системах оперативной аналитической обработки имеет следующие достоинства.
В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP.
В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД.
Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД - меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настройки индексов, то есть больших усилий со стороны администраторов БД. Только при использовании звездообразных схем производительность хорошо настроенных реляционных систем может быть приближена к производительности систем на основе многомерных баз данных.
Онлайн-аналитическая обработка, или OLAP - это эффективная технология обработки данных, в результате чего на основе огромных массивов всевозможных данных выводится итоговая информация. Это мощный продукт, который помогает получать доступ, извлекать и просматривать информацию на ПК, анализируя ее с разных точек зрения.
OLAP - это инструмент, который обеспечивает стратегическую позицию долгосрочного планирования и рассматривает базовую информацию оперативных данных на перспективу 5, 10 и более лет. Данные хранятся в базе с размерностью, которая является их атрибутом. Пользователи могут просматривать один и тот же набор данных с разными атрибутами, в зависимости от целей анализа.
История OLAP
OLAP не является новой концепцией и используется уже на протяжении десятилетий. По сути, происхождение технологии отслеживается еще с 1962 года. Но термин был придуман только в 1993 году автором базы данных Тедом Коддомом, который также установил 12 правил для продукта. Как и во многих других приложениях, концепция подвергалась нескольким этапам эволюции.
История самой OLAP-технологии восходит к 1970 году, когда были выпущены информационные ресурсы Express и первый Olap-сервер. Они были приобретены Oracle в 1995 году и впоследствии стали основой онлайн-аналитической обработки многомерного вычислительного механизма, который известный компьютерный бренд предоставлял в своей базе данных. В 1992 году еще один известный онлайн-аналитический продукт обработки Essbase был выпущен компанией Arbor Software (приобретенной Oracle в 2007 году).
В 1998 году Microsoft выпустила онлайн-аналитический сервер обработки данных MS Analysis Services. Это способствовало популярности технологии и побудило разработку других продуктов. Сегодня функционируют несколько всемирно известных поставщиков, предлагающих Olap-приложения, в том числе IBM, SAS, SAP, Essbase, Microsoft, Oracle, IcCube.
Онлайн-аналитическая обработка
OLAP - это инструмент, который позволяет принимать решения о планируемых событиях. Атипичный Olap-расчет может быть более сложным, чем просто агрегирование данных. Аналитические запросы в минуту (AQM) используются в качестве стандартного эталона для сравнения характеристик различных инструментов. Эти системы должны максимально скрывать пользователей от синтаксиса сложных запросов и обеспечивать согласованное время отклика для всех (независимо от того, насколько они сложны).
Существуют следующие основные характеристики OLAP:
- Многомерные представления данных.
- Поддержка сложных вычислений.
- Временная разведка.
Многомерное представление обеспечивает основу для аналитической обработки посредством гибкого доступа к корпоративным данным. Оно позволяет пользователям анализировать данные в любом измерении и на любом уровне агрегации.
Поддержка сложных вычислений является основой программного обеспечения OLAP.
Временная разведка используется для оценки эффективности любого аналитического приложения на протяжении определенного отрезка времени. Например, в этом месяце по сравнению с прошлым месяцем, в этом месяце по сравнению с тем же месяцем прошлого года.
Многомерная структура данных
Одной из основных характеристик онлайн-аналитической обработки является многомерная структура данных. Куб может иметь несколько измерений. Благодаря такой модели весь процесс интеллектуального OLAP-анализа является простым для менеджеров и руководителей, поскольку объекты, представленные в ячейках, являются бизнес-объектами реального мира. Кроме того, эта модель данных позволяет пользователям обрабатывать не только структурированные массивы, но и неструктурированные и полуструктурированные. Все это делает их особенно популярными для анализа данных и приложений BI.

Основные характеристики OLAP-систем:
- Используют многомерные методы анализа данных.
- Обеспечивают расширенную поддержку базы данных.
- Создают простые в использовании интерфейсы конечных пользователей.
- Поддерживают архитектуру клиент/сервер.
Одним из основных компонентов концепций OLAP является сервер на стороне клиента. Помимо агрегирования и предварительной обработки данных из реляционной базы, он предоставляет расширенные параметры расчета и записи, дополнительные функции, основные расширенные возможности запросов и другие функции.
В зависимости от примера приложения, выбранного пользователем, доступны различные модели данных и инструменты, включая оповещение в реальном времени, функцию для применения сценариев «что, если», оптимизацию и сложные OLAP-отчеты.
Кубическая форма
В основе концепции лежит кубическая форма. Расположение данных в ней показывает, как OLAP придерживается принципа многомерного анализа, в результате чего создается структура данных, предназначенная для быстрого и эффективного анализа.
Куб OLAP также называется «гиперкубом». Он описывается как состоящий из числовых фактов (мер), классифицированных по фасетам (измерениям). Размеры относятся к атрибутам, которые определяют бизнес-проблему. Проще говоря, измерение - это метка, описывающая меру. Например, в отчетах о продажах мерой будет объем продаж, а размеры будут включать период продаж, продавцов, продукт или услугу, а также регион продаж. В отчетности по производственным операциям мерой могут быть общие производственные затраты и единицы продукции. Габаритами будут дата или время производства, этап производства или фаза, даже работники, вовлеченные в производственный процесс.

OLAP-куб данных является краеугольным камнем системы. Данные в кубе организованы с использованием либо звезды, либо схемы снежинок. В центре есть таблица фактов, содержащая агрегаты (меры). Она связана с рядом таблиц измерений, содержащих информацию о мерах. Размеры описывают, как эти меры могут быть проанализированы. Если куб содержит более трех измерений, его часто называют гиперкубом.
Одной из основных функций, принадлежащих кубу, является его статический характер, который подразумевает, что куб не может быть изменен после его разработки. Следовательно, процесс сборки куба и настройки модели данных является решающим шагом на пути к соответствующей обработке данных в архитектуре OLAP.
Объединение данных
Использование агрегаций является основной причиной, по которой запросы обрабатываются намного быстрее в OLAP-инструментах (по сравнению с OLTP). Агрегации представляют собой сводки данных, которые были предварительно рассчитаны во время их обработки. Все члены, хранящиеся в OLAP таблицах измерений, определяют запросы, которые куб может получить.
В кубе скопления информации хранятся в ячейках, координаты которых задаются конкретными размерами. Количество агрегатов, которые может содержать куб, зависит от всех возможных комбинаций элементов измерения. Поэтому типичный куб в приложении может содержать чрезвычайно большое количество агрегатов. Предварительное вычисление будет выполнено только для ключевых агрегатов, которые распределяются по всему аналитическому кубу онлайн-аналитики. Это значительно сократит время, необходимое для определения любых агрегаций при выполнении запроса в модели данных.
Есть также два варианта, связанных с агрегациями, с помощью которых можно повысить производительность готового куба: создать агрегацию кеша возможностей и использовать агрегацию на основе анализа запросов пользователей.
Принцип работы
Обычно анализ оперативной информации, полученной из транзакций, может выполняться с использованием простой электронной таблицы (значения данных представлены в строках и столбцах). Это хорошо, учитывая двумерный характер данных. В случае OLAP есть отличия, что связано с многомерным массивом данных. Поскольку их часто получают из разных источников, электронная таблица не всегда может эффективно их обрабатывать.
Куб решает эту проблему, а также обеспечивает работу OLAP-хранилища данных логичным и упорядоченным образом. Бизнес собирает данные из многочисленных источников и представлен в разных форматах, таких как текстовые файлы, мультимедийные файлы, электронные таблицы Excel, базы данных Access и даже базы данных OLTP.

Все данные собираются в хранилище, наполняемом прямо из источников. В нем необработанная информация, полученная из OLTP и других источников, будет очищена от любых ошибочных, неполных и непоследовательных транзакций.
После очистки и преобразования информация будет храниться в реляционной базе данных. Затем она будет загружена на многомерный OLAP-сервер (или Olap-куб) для анализа. Конечные пользователи, отвечающие за бизнес-приложения, интеллектуальный анализ данных и другие бизнес-операции, получат доступ к необходимой им информации из Olap-куба.
Преимущества модели массива
OLAP - это инструмент, обеспечивающий быструю производительность запросов, которая достигается благодаря оптимизированному хранению, многомерному индексированию и кешированию, что относится к значительным преимуществам системы. Кроме того, преимуществами являются:
- Меньший размер данных на диске.
- Автоматизированное вычисление агрегатов более высокого уровня данных.
- Модели массива обеспечивают естественную индексацию.
- Эффективное извлечение данных достигается за счет предварительной структуризации.
- Компактность для наборов данных с низкой размерностью.
К недостаткам OLAP относится тот факт, что некоторые решения (шаг обработки) могут быть довольно продолжительным, особенно при больших объемах информации. Обычно это исправляется путем выполнения только инкрементной обработки (изучаются данные, которые были изменены).
Основные аналитические операции
Свертка (roll-up/drill-up) также известна как «консолидация». Свертывание включает в себя сбор всех данных, которые могут быть получены, и вычисление всех в одном или нескольких измерениях. Чаще всего это может потребовать применения математической формулы. В качестве OLAP-примера можно рассмотреть розничную сеть с торговыми точками в разных городах. Чтобы определить модели и предвидеть будущие тенденции продаж, данные о них из всех точек «свернуты» в основной отдел продаж компании для консолидации и расчета.
Раскрытие (drill-down). Это противоположность свертыванию. Процесс начинается с большого набора данных, а затем разбивается на его меньшие части, тем самым позволяя пользователям просматривать детали. В примере с розничной сетью аналитик будет анализировать данные о продажах и просматривать отдельные бренды или продукты, которые считаются бестселлерами в каждой из торговых точек в разных городах.

Сечение (Slice and dice). Это процесс, когда аналитические операции включают в себя два действия: вывести определенный набор данных из OLAP-куба («разрезающий» аспект анализа) и просматривать его с разных точек зрения или углов. Это может произойти, когда все данные торговых точек получены и введены в гиперкуб. Аналитик вырезает из OLAP Cube набор данных, относящихся к продажам. Далее он будет просмотрен при анализе продаж отдельных единиц в каждом регионе. В это время другие пользователи могут сосредоточиться на оценке экономической эффективности продаж или оценке эффективности маркетинговой и рекламной кампании.
Поворот (Pivot). В нем поворачивают оси данных, чтобы обеспечить замену представления информации.
Разновидности баз данных
В принципе, это типичный OLAP-куб, который реализует аналитическую обработку многомерных данных с помощью OLAP Cube или любого куба данных, чтобы аналитический процесс мог добавлять размеры по мере необходимости. Любая информация, загружаемая в многомерную базу данных, будет храниться или архивироваться и может быть вызвана, когда потребуется.
| Значение |
|
| Реляционная OLAP (ROLAP) | ROLAP - это расширенная СУБД вместе с многомерным отображением данных для выполнения стандартной реляционной операции |
| Многомерный OLAP (MOLAP) | MOLAP - реализует работу в многомерных данных |
| Гибридная онлайн-аналитическая обработка (HOLAP) | В подходе HOLAP агрегированные итоговые значения хранятся в многомерной базе данных, а подробная информация хранится в реляционной базе. Это обеспечивает как эффективность модели ROLAP, так и производительность модели MOLAP |
| Рабочий стол OLAP (DOLAP) | В Desktop OLAP пользователь загружает часть данных из базы данных локально или на свой рабочий стол и анализирует ее. DOLAP относительно дешевле для развертывания, поскольку он предлагает очень мало функциональных возможностей по сравнению с другими системами OLAP |
| Веб-OLAP (WOLAP) | Web OLAP является системой OLAP, доступной через веб-браузер. WOLAP - это трехуровневая архитектура. Он состоит из трех компонентов: клиент, промежуточное программное обеспечение и сервер базы данных |
| Мобильный OLAP | Мобильный OLAP помогает пользователям получать и анализировать данные OLAP с помощью своих мобильных устройств |
| Пространственный OLAP | SOLAP создается для облегчения управления как пространственными, так и непространственными данными в географической информационной системе (ГИС) |
Существуют менее известные OLAP-системы или технологии, но эти являются основными, которые в настоящее время используют крупные корпорации, бизнес-структуры и даже правительство.

Инструменты OLAP
Инструменты для онлайн-аналитической обработки очень хорошо представлены в Интернете в виде как платных, так и бесплатных версий.
Наиболее популярные из них:
- Dundas BI из Dundas Data Visualization представляет собой основанную на браузере платформу для бизнес-аналитиков и визуализации данных, которая включает интегрированные информационные панели, средства OLAP-отчетов и аналитику данных.
- Yellowfin - платформа бизнес-аналитики, которая представляет собой единое интегрированное решение, разработанное для компаний разных отраслей и масштабов. Эта система настраивается для предприятий в области бухгалтерского учета, рекламы, сельского хозяйства.
- ClicData - это решение для бизнес-аналитиков (BI), предназначенное для использования в основном предприятиями малого и среднего бизнеса. Инструмент позволяет конечным пользователям создавать отчеты и информационные панели. Board создан для объединения бизнес-аналитики, управления корпоративной эффективностью и представляет собой полнофункциональную систему, которая обслуживает компании среднего и корпоративного уровня.
- Domo - это облачный пакет управления бизнесом, который объединяется с несколькими источниками данных, включая электронные таблицы, базы данных, социальные сети и любое существующее облачное или локальное программное решение.
- InetSoft Style Intelligence - это программная платформа для бизнес-аналитиков, которая позволяет пользователям создавать информационные панели, визуальную технологию анализа OLAP и отчеты с помощью механизма mashup.
- Birst от Infor Company представляет собой сетевое решение для бизнес-аналитиков и анализа, который объединяет идеи различных команд и помогает принимать обоснованные решения. Инструмент позволяет децентрализованным пользователям увеличить модель корпоративных команд.
- Halo - это комплексная система управления цепочками поставок и бизнес-аналитики, которая помогает в планировании бизнеса и прогнозировании запасов для управления цепочками поставок. Система использует данные из всех источников - больших, малых и промежуточных.
- Chartio - это облачное решение для бизнес-аналитиков, которое предоставляет учредителям, бизнес-группам, аналитикам данных и группам продуктов инструменты организации для повседневной работы.
- Exago BI - это веб-решение, предназначенное для внедрения в веб-приложения. Внедрение Exago BI позволяет компаниям всех размеров предоставлять своим клиентам специальную, оперативную и интерактивную отчетность.
Воздействие на бизнес
Пользователь найдет OLAP в большинстве бизнес-приложений в разных отраслях. Используется анализ не только бизнесом, но и другими заинтересованными сторонами.

Некоторые из его наиболее распространенных приложений включают в себя:
- Маркетинговый OLAP-анализ данных.
- Финансовую отчетность, которая охватывает продажи и расходы, составление бюджета и финансовое планирование.
- Управление бизнес-процессами.
- Анализ продаж.
- Маркетинг баз данных.
Отрасли продолжают расти, а это означает, что вскоре пользователи увидят больше приложений OLAP. Многомерная адаптированная обработка обеспечивает более динамический анализ. Именно по этой причине эти OLAP-системы и технологии используются для оценки сценариев «что, если» и альтернативных бизнес-сценариев.
Применение OLAP системы позволяет автоматизировать стратегический уровень управления организацией. OLAP (Online Analytical Processing – аналитическая обработка данных в реальном времени) представляет собой мощную технологию обработки и исследования данных. Системы, построенные на основе технологии OLAP, предоставляют практически безграничные возможности по составлению отчетов, выполнению сложных аналитических расчетов, построению прогнозов и сценариев, разработке множества вариантов планов.
Полноценные OLAP системы появились в начале 90-х годов, как результат развития информационных систем поддержки принятия решений. Они предназначены для преобразования различных, часто разрозненных, данных, в полезную информацию. OLAP системы могут организовать данные в соответствии с некоторым набором критериев. При этом не обязательно, чтобы критерии имели четкие характеристики.
Свое применение OLAP системы нашли во многих вопросах стратегического управления организацией: управление эффективностью бизнеса, стратегическое планирование, бюджетирование, прогнозирование развития, подготовка финансовой отчетности, анализ работы, имитационное моделирование внешней и внутренней среды организации, хранение данных и отчетности.
Структура OLAP системы
В основе работы OLAP системы лежит обработка многомерных массивов данных. Многомерные массивы устроены так, что каждый элемент массива имеет множество связей с другими элементами. Чтобы сформировать многомерный массив, OLAP система должна получить исходные данные из других систем (например, ERP или CRM системы), или через внешний ввод. Пользователь OLAP системы получает необходимые данные в структурированном виде в соответствии со своим запросом. Исходя из указанного порядка действий, можно представить структуру OLAP системы.
В общем виде, структура OLAP системы состоит из следующих элементов:
- база данных . База данных является источником информации для работы OLAP системы. Вид базы данных зависит от вида OLAP системы и алгоритмов работы OLAP сервера. Как правило, используются реляционные базы данных, многомерные базы данных, хранилища данных и т.п.
- OLAP сервер . Он обеспечивает управление многомерной структурой данных и взаимосвязь между базой данных и пользователями OLAP системы.
- пользовательские приложения . Этот элемент структуры OLAP системы осуществляет управление запросами пользователей и формирует результаты обращения к базе данных (отчеты, графики, таблицы и пр.)
В зависимости от способа организации, обработки и хранения данных, OLAP системы могут быть реализованы на локальных компьютерах пользователей или с использованием выделенных серверов.
Существует три основных способа хранения и обработки данных:
- локально . Данные размещаются на компьютерах пользователей. Обработка, анализ и управление данными выполняется на локальных рабочих местах. Такая структура OLAP системы имеет существенные недостатки, связанные со скоростью обработки данных, защищенностью данных и ограниченным применением многомерного анализа.
- реляционные базы данных . Эти базы данных используются при совместной работе OLAP системы с CRM системой или ERP системой . Данные хранятся на сервере этих систем в виде реляционных баз данных или хранилищ данных. OLAP сервер обращается к этим базам данных для формирования необходимых многомерных структур и проведения анализа.
- многомерные базы данных . В этом случае данные организованы в виде специального хранилища данных на выделенном сервере. Все операции с данными осуществляются на этом сервере, который преобразует исходные данные в многомерные структуры. Такие структуры называют OLAP кубом. Источниками данных для формирования OLAP куба являются реляционные базы данных и/или клиентские файлы. Сервер данных осуществляет предварительную подготовку и обработку данных. OLAP сервер работает с OLAP кубом не имея непосредственного доступа к источникам данных (реляционным базам данных, клиентским файлам и др.).
Виды OLAP систем
В зависимости от метода хранения и обработки данных все OLAP системы могут быть разделены на три основных вида.

1. ROLAP (Relational OLAP – реляционные OLAP системы) – этот вид OLAP системы работает с реляционными базами данных. Обращение к данным осуществляется напрямую в реляционную базу данных. Данные хранятся в виде реляционных таблиц. Пользователи имеют возможность осуществлять многомерный анализ как в традиционных OLAP системах. Это достигается за счет применения инструментов SQL и специальных запросов.
Одним из преимуществ ROLAP является возможность более эффективно осуществлять обработку большого объема данных. Другим преимуществом ROLAP является возможность эффективной обработки как числовых, так и текстовых данных.
К недостаткам ROLAP относится низкая производительность (по сравнению с традиционными OLAP системами), т.к. обработку данных осуществляет сервер OLAP. Другим недостатком является ограничение функциональности из-за применения SQL.

2. MOLAP (Multidimensional OLAP – многомерные OLAP системы). Этот вид OLAP систем относится к традиционным системам. Отличие традиционной OLAP системы, от других систем, заключается в предварительной подготовке и оптимизации данных. Эти системы, как правило, используют выделенный сервер, на котором осуществляется предварительная обработка данных. Данные формируются в многомерные массивы – OLAP кубы.
MOLAP системы являются самыми эффективными при обработке данных, т.к. они позволяют легко реорганизовать и структурировать данные под различные запросы пользователей. Аналитические инструменты MOLAP позволяют выполнять сложные расчеты. Другим преимуществом MOLAP является возможность быстрого формирования запросов и получения результатов. Это обеспечивается за счет предварительного формирования OLAP кубов.
К недостаткам MOLAP системы относится ограничение объемов обрабатываемых данных и избыточность данных, т.к. для формирования многомерных кубов, по различным аспектам, данные приходится дублировать.

3. HOLAP (Hybrid OLAP – гибридные OLAP системы). Гибридные OLAP системы представляют собой объединение систем ROLAP и MOLAP. В гибридных системах постарались объединить преимущества двух систем: использование многомерных баз данных и управление реляционными базами данных. HOLAP системы позволяют хранить большое количество данных в реляционных таблицах, а обрабатываемые данные размещаются в предварительно построенных многомерных OLAP кубах. Преимущества этого вида систем заключаются в масштабируемости данных, быстрой обработке данных и гибком доступе к источникам данных.
Существуют и другие виды OLAP систем, но они в большей степени являются маркетинговым ходом производителей, чем самостоятельным видом OLAP системы.
К таким видам относятся:
- WOLAP (Web OLAP). Вид OLAP системы с поддержкой web интерфейса. В этих системах OLAP есть возможность обращаться к базам данных через web интерфейс.
- DOLAP (Desktop OLAP). Этот вид OLAP системы дает возможность пользователям загрузить на локальное рабочее место базу данных и работать с ней локально.
- MobileOLAP . Это функция OLAP систем, которая позволяет работать с базой данных удаленно, с использованием мобильных устройств.
- SOLAP (Spatial OLAP). Этот вид OLAP систем предназначен для обработки пространственных данных. Он появился как результат интеграции географических информационных систем и OLAP системы. Эти системы позволяют обрабатывать данные не только в буквенно-цифровом формате, но и в виде визуальных объектов и векторов.
Преимущества OLAP системы
Применение OLAP системы дает организации возможности по прогнозированию и анализу различных ситуаций, связанных с текущей деятельностью и перспективами развития. Эти системы можно рассматривать как дополнение к системам автоматизации уровня предприятия. Все преимущества OLAP систем напрямую зависят от точности, достоверности и объема исходных данных.
Основными преимуществами OLAP системы являются:
- согласованность исходной информации и результатов анализа . При наличии OLAP системы всегда есть возможность проследить источник информации и определить логическую связь между полученными результатами и исходными данными. Снижается субъективность результатов анализа.
- проведение многовариантного анализа . Применение OLAP системы позволяет получить множество сценариев развития событий на основе набора исходных данных. За счет инструментов анализа можно смоделировать ситуации по принципу «что будет, если».
- управление детализацией . Детальность представления результатов может изменяться в зависимости от потребности пользователей. При этом нет необходимости осуществлять сложные настройки системы и повторять вычисления. Отчет может содержать именно ту информацию, которая необходима для принятия решений.
- выявление скрытых зависимостей . За счет построения многомерных связей появляется возможность выявить и определить скрытые зависимости в различных процессах или ситуациях, которые влияют на производственную деятельность.
- создание единой платформы . За счет применения OLAP системы появляется возможность создать единую платформу для всех процессов прогнозирования и анализа на предприятии. В частности, данные OLAP системы, являются основой для построения прогнозов бюджета, прогноза продаж, прогноза закупок, плана стратегического развития и пр.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Курсовая работа
по дисциплине: Базы данных
Тема: Технология OLAP
Выполнил:
Чижиков Александр Александрович
Введение
1. Классификация OLAP-продуктов
2. OLAP-клиент - OLAP-сервер: "за" и "против"
3. Ядро OLAP системы
3.1 Принципы построения
Заключение
Список использованных источников
Приложения
В ведение
Трудно найти в компьютерном мире человека, который хотя бы на интуитивном уровне не понимал, что такое базы данных и зачем они нужны. В отличие от традиционных реляционных СУБД, концепция OLAP не так широко известна, хотя загадочный термин "кубы OLAP" слышали, наверное, почти все. Что же такое OnLine Analytical Processing?
OLAP - это не отдельно взятый программный продукт, не язык программирования и даже не конкретная технология. Если постараться охватить OLAP во всех его проявлениях, то это совокупность концепций, принципов и требований, лежащих в основе программных продуктов, облегчающих аналитикам доступ к данным. Несмотря на то, что с таким определением вряд ли кто-нибудь не согласится, сомнительно, чтобы оно хоть на йоту приблизило неспециалистов к пониманию предмета. Поэтому в своем стремлении к познанию OLAP лучше идти другим путем. Для начала надо выяснить, зачем аналитикам надо как-то специально облегчать доступ к данным.
Дело в том, что аналитики - это особые потребители корпоративной информации. Задача аналитика - находить закономерности в больших массивах данных. Поэтому аналитик не будет обращать внимания на отдельно взятый факт, ему нужна информация о сотнях и тысячах событий. Кстати, один из существенных моментов, который привел к появлению OLAP - производительность и эффективность. Представим себе, что происходит, когда аналитику необходимо получить информацию, а средства OLAP на предприятии отсутствуют. Аналитик самостоятельно (что маловероятно) или с помощью программиста делает соответствующий SQL-запрос и получает интересующие данные в виде отчета или экспортирует их в электронную таблицу. Проблем при этом возникает великое множество. Во-первых, аналитик вынужден заниматься не своей работой (SQL-программированием) либо ждать, когда за него задачу выполнят программисты - все этоотрицательно сказывается на производительности труда, повышается инфарктно-инсультный уровень и так далее. Во-вторых, один-единственный отчет или таблица, как правило, не спасает гигантов мысли и отцов русского анализа - и всю процедуру придется повторять снова и снова. В-третьих, как мы уже выяснили, аналитики по мелочам не спрашивают - им нужно все и сразу. Это означает (хотя техника и идет вперед семимильными шагами), что сервер корпоративной реляционной СУБД, к которому обращается аналитик, может задуматься глубоко и надолго, заблокировав остальные транзакции.
Концепция OLAP появилась именно для разрешения подобных проблем. Кубы OLAP представляют собой, по сути, мета-отчеты. Разрезая мета-отчеты (кубы, то есть) по измерениям, аналитик получает, фактически, интересующие его "обычные" двумерные отчеты (это не обязательно отчеты в обычном понимании этого термина - речь идет о структурах данных с такими же функциями). Преимущества кубов очевидны - данные необходимо запросить из реляционной СУБД всего один раз - при построении куба. Поскольку аналитики, как правило, не работают с информацией, которая дополняется и меняется "на лету", сформированный куб является актуальным в течение достаточно продолжительного времени. Благодаря этому, не только исключаются перебои в работе сервера реляционной СУБД (нет запросов с тысячами и миллионами строк ответов), но и резко повышается скорость доступа к данным для самого аналитика. Кроме того, как уже отмечалось, производительность повышается и за счет подсчета промежуточных сумм иерархий и других агрегированных значений в момент построения куба.
Конечно, за повышение таким способом производительности надо платить. Иногда говорят, что структура данных просто "взрывается" - куб OLAP может занимать в десятки и даже сотни раз больше места, чем исходные данные.
Теперь, когда мы немного разобрались в том, как работает и для чего служит OLAP, стоит, все же, несколько формализовать наши знания и дать критерии OLAP уже без синхронного перевода на обычный человеческий язык. Эти критерии (всего числом 12) были сформулированы в 1993 году Е.Ф. Коддом - создателем концепции реляционных СУБД и, по совместительству, OLAP. Непосредственно их мы рассматривать не будем, поскольку позднее они были переработаны в так называемый тест FASMI, который определяет требования к продуктам OLAP. FASMI - это аббревиатура от названия каждого пункта теста:
Fast (быстрый). Это свойство означает, что система должна обеспечивать ответ на запрос пользователя в среднем за пять секунд; при этом большинство запросов обрабатываются в пределах одной секунды, а самые сложные запросы должны обрабатываться в пределах двадцати секунд. Недавние исследования показали, что пользователь начинает сомневаться в успешности запроса, если он занимает более тридцати секунд.
Analysis (аналитический). Система должна справляться с любым логическим и статистическим анализом, характерным для бизнес-приложений, и обеспечивает сохранение результатов в виде, доступном для конечного пользователя. Средства анализа могут включать процедуры анализа временных рядов, распределения затрат, конверсии валют, моделирования изменений организационных структур и некоторые другие.
Shared (разделяемый). Система должна предоставлять широкие возможности разграничения доступа к данным и одновременной работы многих пользователей.
Multidimensional (многомерный). Система должна обеспечивать концептуально многомерное представление данных, включая полную поддержку множественных иерархий.
Information (информация). Мощность различных программных продуктов характеризуется количеством обрабатываемых входных данных. Разные OLAP-системы имеют разную мощность: передовые OLAP-решения могут оперировать, по крайней мере, в тысячу раз большим количеством данных по сравнению с самыми маломощными. При выборе OLAP-инструмента следует учитывать целый ряд факторов, включая дублирование данных, требуемую оперативную память, использование дискового пространства, эксплуатационные показатели, интеграцию с информационными хранилищами и т.п.
1. Классификация OLAP-продуктов
Итак, суть OLAP заключается в том, что исходная для анализа информация представляется в виде многомерного куба, и обеспечивается возможность произвольно манипулировать ею и получать нужные информационные разрезы - отчеты. При этом конечный пользователь видит куб как многомерную динамическую таблицу, которая автоматически суммирует данные (факты) в различных разрезах (измерениях), и позволяет интерактивно управлять вычислениями и формой отчета. Выполнение этих операций обеспечивается OLAP-машиной (или машиной OLAP-вычислений).
На сегодняшний день в мире разработано множество продуктов, реализующих OLAP-технологии. Чтобы легче было ориентироваться среди них, используют классификации OLAP-продуктов: по способу хранения данных для анализа и по месту нахождения OLAP-машины. Рассмотрим подробнее каждую категорию OLAP-продуктов.
Начну я с классификации по способу хранения данных. Напомню, что многомерные кубы строятся на основе исходных и агрегатных данных. И исходные и агрегатные данные для кубов могут храниться как в реляционных, так и многомерных базах данных. Поэтому в настоящее время применяются три способа хранения данных: MOLAP (Multidimensional OLAP), ROLAP (Relational OLAP) и HOLAP (Hybrid OLAP). Соответственно, OLAP-продукты по способу хранения данных делятся на три аналогичные категории:
1.В случае MOLAP, исходные и агрегатные данные хранятся в многомерной БД или в многомерном локальном кубе.
2.В ROLAP-продуктах исходные данные хранятся в реляционных БД или в плоских локальных таблицах на файл-сервере. Агрегатные данные могут помещаться в служебные таблицы в той же БД. Преобразование данных из реляционной БД в многомерные кубы происходит по запросу OLAP-средства.
3.В случае использования HOLAP архитектуры исходные данные остаются в реляционной базе, а агрегаты размещаются в многомерной. Построение OLAP-куба выполняется по запросу OLAP-средства на основе реляционных и многомерных данных.
Следующая классификация - по месту размещения OLAP-машины. По этому признаку OLAP-продукты делятся на OLAP-серверы и OLAP-клиенты:
В серверных OLAP-средствах вычисления и хранение агрегатных данных выполняются отдельным процессом - сервером. Клиентское приложение получает только результаты запросов к многомерным кубам, которые хранятся на сервере. Некоторые OLAP-серверы поддерживают хранение данных только в реляционных базах, некоторые - только в многомерных. Многие современные OLAP-серверы поддерживают все три способа хранения данных: MOLAP, ROLAP и HOLAP.
OLAP-клиент устроен по-другому. Построение многомерного куба и OLAP-вычисления выполняются в памяти клиентского компьютера. OLAP-клиенты также делятся на ROLAP и MOLAP. А некоторые могут поддерживать оба варианта доступа к данным.
У каждого из этих подходов, есть свои "плюсы" и "минусы". Вопреки распространенному мнению о преимуществах серверных средств перед клиентскими, в целом ряде случаев применение OLAP-клиента для пользователей может оказаться эффективнее и выгоднее использования OLAP-сервера.
2. OLAP-клиент - OLAP-сервер: "за" и "против"
При построении информационной системы OLAP-функциональность может быть реализована как серверными, так и клиентскими OLAP-средствами. На практике выбор является результатом компромисса эксплуатационных показателей и стоимости программного обеспечения.
Объем данных определяется совокупностью следующих характеристик: количество записей, количество измерений, количество элементов измерений, длина измерений и количество фактов. Известно, что OLAP-сервер может обрабатывать большие объемы данных, чем OLAP-клиент при равной мощности компьютера. Это объясняется тем, что OLAP-сервер хранит на жестких дисках многомерную базу данных, содержащую заранее вычисленные кубы.
Клиентские программы в момент выполнения OLAP-операций выполняют к ней запросы на SQL-подобном языке, получая не весь куб, а его отображаемые фрагменты. OLAP-клиент в момент работы должен иметь в оперативной памяти весь куб. В случае ROLAP-архитектуры, необходимо предварительно загрузить в память весь используемый для вычисления куба массив данных. Кроме того, при увеличении числа измерений, фактов или элементов измерений количество агрегатов растет в геометрической прогрессии. Таким образом, объем данных, обрабатываемых OLAP-клиентом, находится в прямой зависимости от объема оперативной памяти ПК пользователя.
Однако заметим, что большинство OLAP-клиентов обеспечивают выполнение распределенных вычислений. Поэтому под количеством обрабатываемых записей, которое ограничивает работу клиентского OLAP-средства, понимается не объем первичных данных корпоративной БД, а размер агрегированной выборки из нее. OLAP-клиент генерирует запрос к СУБД, в котором описываются условия фильтрации и алгоритм предварительной группировки первичных данных. Сервер находит, группирует записи и возвращает компактную выборку для дальнейших OLAP-вычислений. Размер этой выборки может быть в десятки и сотни раз меньше объема первичных, не агрегированных записей. Следовательно, потребность такого OLAP-клиента в ресурсах ПК существенно снижается.
Кроме того, на количество измерений накладывают ограничения возможности человеческого восприятия. Известно, что средний человек может одновременно оперировать 3-4, максимум 8 измерениями. При большем количестве измерений в динамической таблице восприятие информации существенно затрудняется. Этот фактор следует учитывать при предварительном расчете оперативной памяти, которая может потребоваться OLAP-клиенту.
Длина измерений также влияет на размер адресного пространства OLAP-средства, занятого при вычислении OLAP-куба. Чем длиннее измерения, тем больше ресурсов требуется для выполнения предварительной сортировки многомерного массива, и наоборот. Только короткие измерения в исходных данных - еще один аргумент в пользу OLAP-клиента.
Эта характеристика определяется двумя рассмотренными выше факторами: объемом обрабатываемых данных и мощностью компьютеров. При возрастании количества, например, измерений, производительность всех OLAP-средств снижается за счет значительного увеличения количества агрегатов, но при этом темпы снижения разные. Продемонстрируем эту зависимость на графике.
Схема 1. Зависимость производительности клиентских и серверных OLAP-средств от увеличения объема данных
Скоростные характеристики OLAP-сервера менее чувствительны к росту объема данных. Это объясняется различными технологиями обработки запросов пользователей OLAP-сервером и OLAP-клиентом. Например, при операции детализации OLAP-сервер обращается к хранимым данным и "вытягивает" данные этой "ветки". OLAP-клиент же вычисляет весь набор агрегатов в момент загрузки. Однако до определенного объема данных производительность серверных и клиентских средств является сопоставимой. Для OLAP-клиентов, поддерживающих распределенные вычисления, область сопоставимости производительности может распространяться на объемы данных, покрывающие потребности в OLAP-анализе огромного количества пользователей. Это подтверждают результаты внутреннего тестирования MS OLAP Server и OLAP-клиента "Контур Стандарт". Тест выполнен на ПК IBM PC Pentium Celeron 400 МГц, 256 Mb для выборки в 1 миллион уникальных (т.е. агрегированных) записей с 7 измерениями, содержащими от 10 до 70 членов. Время загрузки куба в обоих случаях не превышает 1 секунды, а выполнение различных OLAP-операций (drill up, drill down, move, filter и др.) выполняется за сотые доли секунды.
Когда размер выборки превысит объем оперативной памяти, начинается обмен (swapping) с диском и производительность OLAP-клиента резко падает. Только с этого момента можно говорить о преимуществе OLAP-сервера.
Следует помнить, что точка "перелома" определяет границу резкого удорожания OLAP-решения. Для задач каждого конкретного пользователя эта точка легко определяется по тестам производительности OLAP-клиента. Такие тесты можно получить у компании-разработчика.
Кроме того, стоимость серверного OLAP-решения растет при увеличении количества пользователей. Дело в том, что OLAP-сервер выполняет вычисления для всех пользователей на одном компьютере. Соответственно, чем больше количество пользователей, тем больше оперативной памяти и процессорной мощности. Таким образом, если объемы обрабатываемых данных лежат в области сопоставимой производительности серверных и клиентских систем, то при прочих равных условиях, использование OLAP-клиента будет выгоднее.
Использование OLAP-сервера в "классической" идеологии предусматривает выгрузку данных реляционных СУБД в многомерную БД. Выгрузка выполняется за определенный период, поэтому данные OLAP-сервера не отражают состояние на текущий момент. Этого недостатка лишены только те OLAP-серверы, которые поддерживают ROLAP-режим работы.
Аналогичным образом, целый ряд OLAP-клиентов позволяет реализовать ROLAP- и Desktop-архитектуру с прямым доступом к БД. Это обеспечивает анализ исходных данных в режиме on-line.
OLAP-сервер предъявляет минимальные требования к мощности клиентских терминалов. Объективно, требования OLAP-клиента выше, т.к. он производит вычисления в оперативной памяти ПК пользователя. Состояние парка аппаратных средств конкретной организации - важнейший показатель, который должен быть учтен при выборе OLAP-средства. Но и здесь есть свои "плюсы" и "минусы". OLAP-сервер не использует огромную вычислительную мощность современных персональных компьютеров. В случае, если организация уже имеет парк современных ПК, неэффективно применять их лишь в качестве отображающих терминалов и в тоже время делать дополнительные затраты на центральный сервер.
Если мощность компьютеров пользователей "оставляет желать лучшего", OLAP-клиент будет работать медленно или не сможет работать вовсе. Покупка одного мощного сервера может оказаться дешевле модернизации всех ПК.
Здесь полезно принять во внимание тенденции в развитии аппаратного обеспечения. Поскольку объемы данных для анализа являются практически константой, то стабильный рост мощности ПК будет приводить к расширению возможностей OLAP-клиентов и вытеснению ими OLAP-серверов в сегмент очень больших баз данных.
При использовании OLAP-сервера по сети на ПК клиента передаются только данные для отображения, в то время как OLAP-клиент получает весь объем данных первичной выборки.
Поэтому там, где применяется OLAP-клиент, сетевой трафик будет выше.
Но, при применении OLAP-сервера операции пользователя, например, детализация, порождают новые запросы к многомерной базе, а, значит, новую передачу данных. Выполнение же OLAP-операций OLAP-клиентом производится в оперативной памяти и, соответственно, не вызывает новых потоков данных в сети.
Также необходимо отметить, что современное сетевое аппаратное обеспечение обеспечивает высокий уровень пропускной способности.
Поэтому в подавляющем большинстве случаев анализ БД "средних" размеров с помощью OLAP-клиента не будет тормозить работу пользователя.
Стоимость OLAP-сервера достаточно высока. Сюда же следует плюсовать стоимость выделенного компьютера и постоянные затраты на администрирование многомерной базы. Кроме того, внедрение и сопровождение OLAP-сервера требует от персонала достаточно высокой квалификации.
Стоимость OLAP-клиента на порядок ниже стоимости OLAP-сервера. Администрирования и дополнительного технического оборудования под сервер не требуется. К квалификации персонала при внедрении OLAP-клиента высоких требований не предъявляется. OLAP-клиент может быть внедрен значительно быстрее OLAP-сервера.
Разработка аналитических приложений с помощью клиентских OLAP-средств - процесс быстрый и не требующий специальной подготовки исполнителя. Пользователь, знающий физическую реализацию базы данных, может разработать аналитическое приложение самостоятельно, без привлечения ИТ-специалиста. При использовании OLAP-сервера необходимо изучить 2 разные системы, иногда от различных поставщиков, - для создания кубов на сервере, и для разработки клиентского приложения. OLAP-клиент предоставляет единый визуальный интерфейс для описания кубов и настройки к ним пользовательских интерфейсов.
Рассмотрим процесс создания OLAP-приложения с помощью клиентского инструментального средства.
Схема 2. Создание OLAP-приложения с помощью клиентского ROLAP-средства
Принцип работы ROLAP-клиентов - предварительное описание семантического слоя, за которым скрывается физическая структура исходных данных. При этом источниками данных могут быть: локальные таблицы, РСУБД. Список поддерживаемых источников данных определяется конкретным программным продуктом. После этого пользователь может самостоятельно манипулировать понятными ему объектами в терминах предметной области для создания кубов и аналитических интерфейсов.
Принцип работы клиента OLAP-сервера иной. В OLAP-сервере при создании кубов пользователь манипулирует физическими описаниями БД.
При этом в самом кубе создаются пользовательские описания. Клиент OLAP-сервера настраивается только на куб.
Поясним принцип работы ROLAP-клиента на примере создания динамического отчета о продажах (см. схему 2). Пусть исходные данные для анализа хранятся в двух таблицах: Sales и Deal.
При создании семантического слоя источники данных - таблицы Sales и Deal - описываются понятными конечному пользователю терминами и превращаются в "Продукты" и "Сделки". Поле "ID" из таблицы "Продукты" переименовывается в "Код", а "Name" - в "Товар" и т.д.
Затем создается бизнес-объект "Продажи". Бизнес-объект - это плоская таблица, на основе которой формируется многомерный куб. При создании бизнес-объекта таблицы "Продукты" и "Сделки" объединяются по полю "Код" товара. Поскольку для отображения в отчете не потребуются все поля таблиц - бизнес-объект использует только поля "Товар", "Дата" и "Сумма".
Далее на базе бизнес-объекта создается OLAP-отчет. Пользователь выбирает бизнес-объект и перетаскивает его атрибуты в области колонок или строк таблицы отчета. В нашем примере на базе бизнес-объекта "Продажи" создан отчет по продажам товаров по месяцам.
При работе с интерактивным отчетом пользователь может задавать условия фильтрации и группировки такими же простыми движениями "мышью". В этот момент ROLAP-клиент обращается к данным в кэше. Клиент же OLAP-сервера генерирует новый запрос к многомерной базе данных. Например, применив в отчете о продажах фильтр по товарам, можно получить отчет о продажах интересующих нас товаров.
Все настройки OLAP-приложения могут храниться в выделенном репозитории метаданных, в приложении или в системном репозитории многомерной базы данных. Реализация зависит от конкретного программного продукта.
Итак, в каких случаях применение OLAP-клиента для пользователей может оказаться эффективнее и выгоднее использования OLAP-сервера?
Экономическая целесообразность применения OLAP-сервера возникает, когда объемы данных очень велики и непосильны для OLAP-клиента, иначе более оправдано применение последнего. В этом случае OLAP-клиент сочетает в себе высокие характеристики производительности и низкую стоимость.
Мощные ПК аналитиков - еще один довод в пользу OLAP-клиентов. При применении OLAP-сервера эти мощности не используются. Среди преимуществ OLAP-клиентов можно также назвать следующее:
Затраты на внедрение и сопровождение OLAP-клиента существенно ниже, чем затраты на OLAP-сервер.
При использовании OLAP-клиента со встроенной машиной передача данных по сети производится один раз. При выполнении OLAP-операций новых потоков данных не порождается.
Настройка ROLAP-клиентов упрощена за счет исключения промежуточного звена - создания многомерной базы.
3. Ядро OLAP системы
3.1 Принципы построения
приложение клиентский ядро данные
Из уже сказанного, ясно, что механизм OLAP является на сегодня одним из популярных методов анализа данных. Есть два основных подхода к решению этой задачи. Первый из них называется Multidimensional OLAP (MOLAP) - реализация механизма при помощи многомерной базы данных на стороне сервера, а второй Relational OLAP (ROLAP) - построение кубов "на лету" на основе SQL запросов к реляционной СУБД. Каждый из этих подходов имеет свои плюсы и минусы. Их сравнительный анализ выходит за рамки этой работы. Здесь будет описана только реализация ядра настольного ROLAP модуля.
Такая задача возникла после применения ROLAP системы, построенной на основе компонентов Decision Cube, входящих в состав Borland Delphi. К сожалению, использование этого набора компонент показало низкую производительность на больших объемах данных. Остроту этой проблемы можно снизить, стараясь отсечь как можно больше данных перед подачей их для построения кубов. Но этого не всегда бывает достаточно.
В Интернете и прессе можно найти много информации об OLAP системах, но практически нигде не сказано о том, как это устроено внутри.
Схема работы:
Общую схему работы настольной OLAP системы можно представить следующим образом:
Схема 3. Работа настольной OLAP системы
Алгоритм работы следующий:
1.Получение данных в виде плоской таблицы или результата выполнения SQL запроса.
2.Кэширование данных и преобразование их к многомерному кубу.
3.Отображение построенного куба при помощи кросс-таблицы или диаграммы и т.п. В общем случае, к одному кубу может быть подключено произвольное количество отображений.
Рассмотрим как подобная система может быть устроена внутри. Начнем мы это с той стороны, которую можно посмотреть и пощупать, то есть с отображений. Отображения, используемые в OLAP системах, чаще всего бывают двух видов - кросс-таблицы и диаграммы. Рассмотрим кросс-таблицу, которая является основным и наиболее распространенным способом отображения куба.
На приведенном ниже рисунке, желтым цветом отображены строки и столбцы, содержащие агрегированные результаты, светло-серым цветом отмечены ячейки, в которые попадают факты и темно-серым ячейки, содержащие данные размерностей.
Таким образом, таблицу можно разделить на следующие элементы, с которыми мы и будем работать в дальнейшем:
Заполняя матрицу с фактами, мы должны действовать следующим образом:
На основании данных об измерениях определить координаты добавляемого элемента в матрице.
Определить координаты столбцов и строк итогов, на которые влияет добавляемый элемент.
Добавить элемент в матрицу и соответствующие столбцы и строки итогов.
При этом нужно отметить то, что полученная матрица будет сильно разреженной, почему ее организация в виде двумерного массива (вариант, лежащий на поверхности) не только нерациональна, но, скорее всего, и невозможна в связи с большой размерностью этой матрицы, для хранения которой не хватит никакого объема оперативной памяти. Например, если наш куб содержит информацию о продажах за один год, и если в нем будет всего 3 измерения - Клиенты (250), Продукты (500) и Дата (365), то мы получим матрицу фактов следующих размеров: кол-во элементов = 250 х 500 х 365 = 45 625 000. И это при том, что заполненных элементов в матрице может быть всего несколько тысяч. Причем, чем больше количество измерений, тем более разреженной будет матрица.
Поэтому, для работы с этой матрицей нужно применить специальные механизмы работы с разреженными матрицами. Возможны различные варианты организации разреженной матрицы. Они довольно хорошо описаны в литературе по программированию, например, в первом томе классической книги "Искусство программирования" Дональда Кнута.
Рассмотрим теперь, как можно определить координаты факта, зная соответствующие ему измерения. Для этого рассмотрим подробнее структуру заголовка:
При этом можно легко найти способ определения номеров соответствующей ячейки и итогов, в которые она попадает. Здесь можно предложить несколько подходов. Один из них - это использование дерева для поиска соответствующих ячеек. Это дерево может быть построено при проходе по выборке. Кроме того, можно легко определить аналитическую рекуррентную формулу для вычисления требуемой координаты.
Данные, хранящиеся в таблице необходимо преобразовать для их использования. Так, в целях повышения производительности при построении гиперкуба, желательно находить уникальные элементы, хранящиеся в столбцах, являющихся измерениями куба. Кроме того, можно производить предварительное агрегирование фактов для записей, имеющих одинаковые значения размерностей. Как уже было сказано выше, для нас важны уникальные значения, имеющиеся в полях измерений. Тогда для их хранения можно предложить следующую структуру:
Схема 4. Структура хранения уникальных значений
При использовании такой структуры мы значительно снижаем потребность в памяти. Что довольно актуально, т.к. для увеличения скорости работы желательно хранить данные в оперативной памяти. Кроме того, хранить можно только массив элементов, а их значения выгружать на диск, так как они будут нам требоваться только при выводе кросс-таблицы.
Описанные выше идеи были положены в основу при создании библиотеки компонентов CubeBase.
Схема 5. Структура библиотеки компонентов CubeBase
TСubeSource осуществляет кэширование и преобразование данных во внутренний формат, а также предварительное агрегирование данных. Компонент TСubeEngine осуществляет вычисление гиперкуба и операции с ним. Фактически, он является OLAP-машиной, осуществляющей преобразование плоской таблицы в многомерный набор данных. Компонент TCubeGrid выполняет вывод на экран кросс-таблицы и управление отображением гиперкуба. TСubeChart позволяет увидеть гиперкуб в виде графиков, а компонент TСubePivote управляет работой ядра куба.
Итак, мной была рассмотрена архитектура и взаимодействие компонентов, которые могут быть использованы для построения OLAP машины. Теперь рассмотрим подробнее внутреннее устройство компонентов.
Первым этапом работы системы будет загрузка данных и преобразование их во внутренний формат. Закономерным будет вопрос - а зачем это надо, ведь можно просто использовать данные из плоской таблицы, просматривая ее при построении среза куба. Для того чтобы ответить на этот вопрос, рассмотрим структуру таблицы с точки зрения OLAP машины. Для OLAP системы колонки таблицы могут быть либо фактами, либо измерениями. При этом логика работы с этими колонками будет разная. В гиперкубе измерения фактически являются осями, а значения измерений - координатами на этих осях. При этом куб будет заполнен сильно неравномерно - будут сочетания координат, которым не будут соответствовать никакие записи и будут сочетания, которым соответствует несколько записей в исходной таблице, причем первая ситуация встречается чаще, то есть куб будет похож на вселенную - пустое пространство, в отдельных местах которого встречаются скопления точек (фактов). Таким образом, если мы при начальной загрузке данных произведем преагрегирование данных, то есть объединим записи, которые имеют одинаковые значения измерений, рассчитав при этом предварительные агрегированные значения фактов, то в дальнейшем нам придется работать с меньшим количеством записей, что повысит скорость работы и уменьшит требования к объему оперативной памяти.
Для построения срезов гиперкуба нам необходимы следующие возможности - определение координат (фактически значения измерений) для записей таблицы, а также определение записей, имеющих конкретные координаты (значения измерений). Рассмотрим каким образом можно реализовать эти возможности. Для хранения гиперкуба проще всего использовать базу данных своего внутреннего формата.
Схематически преобразования можно представить следующим образом:
Схема 6. Преобразование базы данных внутреннего формата в нормализованную базу данных
То есть вместо одной таблицы мы получили нормализованную базу данных. Вообще-то нормализация снижает скорость работы системы, - могут сказать специалисты по базам данных, и в этом они будут безусловно правы, в случае когда нам надо получить значения для элементов словарей (в нашем случае значения измерений). Но все дело в том, что нам эти значения на этапе построения среза вообще не нужны. Как уже было сказано выше, нас интересуют только координаты в нашем гиперкубе, поэтому определим координаты для значений измерений. Самым простым будет перенумеровать значения элементов. Для того, чтобы в пределах одного измерения нумерация была однозначной, предварительно отсортируем списки значений измерений (словари, выражаясь терминами БД) в алфавитном порядке. Кроме того, перенумеруем и факты, причем факты преагрегированные. Получим следующую схему:
Схема 7. Перенумерация нормализованной БД для определения координат значений измерений
Теперь осталось только связать элементы разных таблиц между собой. В теории реляционных баз данных это осуществляется при помощи специальных промежуточных таблиц. Нам достаточно каждой записи в таблицах измерений поставить в соответствие список, элементами которого будут номера фактов, при формировании которых использовались эти измерения (то есть определить все факты, имеющие одинаковое значение координаты, описываемой этим измерением). Для фактов соответственно каждой записи поставим в соответствие значения координат, по которым она расположена в гиперкубе. В дальнейшем везде под координатами записи в гиперкубе будут пониматься номера соответствующих записей в таблицах значений измерений. Тогда для нашего гипотетического примера получим следующий набор, определяющий внутреннее представление гиперкуба:
Схема 8. Внутреннее представление гиперкуба
Такое будет у нас внутреннее представление гиперкуба. Так как мы делаем его не для реляционной базы данных, то в качестве полей связи значений измерений используются просто поля переменной длины (в РБД такое сделать мы бы не смогли, так как там количество колонок таблицы определено заранее).
Можно было бы попытаться использовать для реализации гиперкуба набор временных таблиц, но этот метод обеспечит слишком низкое быстродействие (пример - набор компонент Decision Cube), поэтому будем использовать свои структуры хранения данных.
Для реализации гиперкуба нам необходимо использовать структуры данных, которые обеспечат максимальное быстродействие и минимальные расходы оперативной памяти. Очевидно, что основными у нас будут структуры для хранения словарей и таблицы фактов. Рассмотрим задачи, которые должен выполнять словарь с максимальной скоростью:
проверка наличия элемента в словаре;
добавление элемента в словарь;
поиск номеров записей, имеющих конкретное значение координаты;
поиск координаты по значению измерения;
поиск значения измерения по его координате.
Для реализации этих требований можно использовать различные типы и структуры данных. Например, можно использовать массивы структур. В реальном случае к этим массивам необходимы дополнительные механизмы индексации, которые позволят повысить скорость загрузки данных и получения информации.
Для оптимизации работы гиперкуба необходимо определить то, какие задачи необходимо решать в первоочередном порядке, и по каким критериям нам надо добиваться повышения качества работы. Главным для нас является повышение скорости работы программы, при этом желательно, чтобы требовался не очень большой объем оперативной памяти. Повышение быстродействия возможно за счет введения дополнительных механизмов доступа к данным, например, введение индексирования. К сожалению, это повышает накладные расходы оперативной памяти. Поэтому определим, какие операции нам необходимо выполнять с наибольшей скоростью. Для этого рассмотрим отдельные компоненты, реализующие гиперкуб. Эти компоненты имеют два основных типа - измерение и таблица фактов. Для измерения типовой задачей будет:
добавление нового значения;
определение координаты по значению измерения;
определение значения по координате.
При добавлении нового значения элемента нам необходимо проверить, есть ли у нас уже такое значение, и если есть, то не добавлять новое, а использовать имеющуюся координату, в противном случае необходимо добавить новый элемент и определить его координату. Для этого необходим способ быстрого поиска наличия нужного элемента (кроме того, такая задача возникает и при определении координаты по значению элемента). Для этого оптимальным будет использование хеширование. При этом оптимальной структурой будет использование хеш-деревьев, в которых будем хранить ссылки на элементы. При этом элементами будут строки словаря измерения. Тогда структуру значения измерения можно представить следующим образом:
PFactLink = ^TFactLink;
TFactLink = record
FactNo: integer; // индекс факта в таблице
TDimensionRecord = record
Value: string; // значение измерения
Index: integer; // значение координаты
FactLink: PFactLink; // указатель на начало списка элементов таблицы фактов
И в хеш-дереве будем хранить ссылки на уникальные элементы. Кроме того, нам необходимо решить задачу обратного преобразования - по координате определить значение измерения. Для обеспечения максимальной производительности надо использовать прямую адресацию. Поэтому можно использовать еще один массив, индекс в котором является координатой измерения, а значение - ссылка на соответствующую запись в словаре. Однако можно поступить проще (и сэкономить при этом на памяти), если соответствующим образом упорядочить массив элементов так, чтобы индекс элемента и был его координатой.
Организация же массива, реализующего список фактов, не представляет особых проблем ввиду его простой структуры. Единственное замечание будет такое, что желательно рассчитывать все способы агрегации, которые могут понадобиться, и которые можно рассчитывать инкрементно (например, сумма).
Итак, мы описали способ хранения данных в виде гиперкуба. Он позволяет сформировать набор точек в многомерном пространстве на основе информации, находящейся в хранилище данных. Для того, чтобы человек мог иметь возможность работы с этими данными, их необходимо представить в виде, удобном для обработки. При этом в качестве основных видов представления данных используются сводная таблица и графики. Причем оба этих способа фактически представляют собой проекции гиперкуба. Для того, чтобы обеспечить максимальную эффективность при построения представлений, будем отталкиваться от того, что представляют собой эти проекции. Начнем рассмотрение со сводной таблицы, как с наиболее важной для анализа данных.
Найдем способы реализации такой структуры. Можно выделить три части, из которых состоит сводная таблица: это заголовки строк, заголовки столбцов и собственно таблица агрегированных значений фактов. Самым простым способом представления таблицы фактов будет использование двумерного массива, размерность которого можно определить, построив заголовки. К сожалению, самый простой способ будет самым неэффективным, потому что таблица будет сильно разреженной, и память будет расходоваться крайне неэффективно, в результате чего можно будет строить только очень малые кубы, так как иначе памяти может не хватить. Таким образом, нам необходимо подобрать для хранения информации такую структуру данных, которая обеспечит максимальную скорость поиска/добавления нового элемента и в то же время минимальный расход оперативной памяти. Этой структурой будут являться так называемые разреженные матрицы, про которые более подробно можно прочесть у Кнута. Возможны различные способы организации матрицы. Для того, чтобы выбрать подходящий нам вариант, рассмотрим изначально структуру заголовков таблицы.
Заголовки имеют четкую иерархическую структуру, поэтому естественно будет предположить для их хранения использовать дерево. При этом схематически структуру узла дерева можно изобразить следующим образом:
Приложение С
При этом в качестве значения измерения логично хранить ссылку на соответствующий элемент таблицы измерений многомерного куба. Это позволит сократить затраты памяти для хранения среза и ускорить работу. В качестве родительских и дочерних узлов также используются ссылки.
Для добавления элемента в дерево необходимо иметь информацию о его местоположении в гиперкубе. В качестве такой информации надо использовать его координату, которая хранится в словаре значений измерения. Рассмотрим схему добавления элемента в дерево заголовков сводной таблицы. При этом в качестве исходной информации используем значения координат измерений. Порядок, в котором эти измерения перечислены, определяется требуемым способом агрегирования и совпадает с уровнями иерархии дерева заголовков. В результате работы необходимо получить список столбцов или строк сводной таблицы, в которые необходимо осуществить добавление элемента.
Приложение D
В качестве исходных данных для определения этой структуры используем координаты измерений. Кроме того, для определенности, будем считать, что мы определяем интересующий нас столбец в матрице (как будем определять строку рассмотрим чуть позже, так как там удобнее применять другие структуры данных, причина такого выбора также см. ниже). В качестве координат возьмем целые числа - номера значений измерений, которые можно определить так, как описано выше.
Итак, после выполнения этой процедуры получим массив ссылок на столбцы разреженной матрицы. Теперь необходимо выполнить все необходимые действия со строками. Для этого внутри каждого столбца необходимо найти нужный элемент и добавить туда соответствующее значение. Для каждого из измерений в коллекции необходимо знать количество уникальных значений и собственно набор этих значений.
Теперь рассмотрим, в каком виде необходимо представить значения внутри столбцов - то есть как определить требуемую строку. Для этого можно использовать несколько подходов. Самым простым было бы представить каждый столбец в виде вектора, но так как он будет сильно разреженным, то память будет расходоваться крайне неэффективно. Чтобы избежать этого, применим структуры данных, которые обеспечат большую эффективность представления разреженных одномерных массивов (векторов). Самой простой из них будет обычный список, одно- или двусвязный, однако он неэкономичен с точки зрения доступа к элементам. Поэтому будем использовать дерево, которое обеспечит более быстрый доступ к элементам.
Например, можно использовать точно такое же дерево, как и для столбцов, но тогда пришлось бы для каждого столбца заводить свое собственное дерево, что приведет к значительным накладным расходам памяти и времени обработки. Поступим чуть хитрее - заведем одно дерево для хранения всех используемых в строках комбинаций измерений, которое будет идентично вышеописанному, но его элементами будут не указатели на строки (которых нет как таковых), а их индексы, причем сами значения индексов нас не интересуют и используются только как уникальные ключи. Затем эти ключи будем использовать для поиска нужного элемента внутри столбца. Сами же столбцы проще всего представить в виде обычного двоичного дерева. Графически полученную структуру можно представить следующим образом:
Схема 9. Изображение сводной таблицы в виде двоичного дерева
Для определения соответствующих номеров строк можно использовать такую же процедуру, что и описанная выше процедура определения столбцов сводной таблицы. При этом номера строк являются уникальными в пределах одной сводной таблицы и идентифицируют элементы в векторах, являющихся столбцами сводной таблицы. Наиболее простым вариантом генерации этих номеров будет ведение счетчика и инкремент его на единицу при добавлении нового элемента в дерево заголовков строк. Сами эти вектора столбцов проще всего хранить в виде двоичных деревьев, где в качестве ключа используется значение номера строки. Кроме того, возможно также и использование хеш-таблиц. Так как процедуры работы с этими деревьями детально рассмотрены в других источниках, то останавливаться на этом не будем и рассмотрим общую схему добавления элемента в столбец.
В обобщенном виде последовательность действий для добавления элемента в матрицу можно описать следующим образом:
1.Определить номера строк, в которые добавляются элементы
2.Определить набор столбцов, в которые добавляются элементы
3.Для всех столбцов найти элементы с нужными номерами строк и добавить к ним текущий элемент (добавление включает в себя подсоединение нужного количества значений фактов и вычисление агрегированных значений, которые можно определить инкрементально).
После выполнения этого алгоритма получим матрицу, представляющую собой сводную таблицу, которую нам было необходимо построить.
Теперь пара слов про фильтрацию при построении среза. Проще всего ее осуществить как раз на этапе построения матрицы, так как на этом этапе имеется доступ ко всем требуемым полям, и, кроме того, осуществляется агрегация значений. При этом, во время получения записи из кэша, проверяется ее соответствие условиям фильтрации, и в случае его несоблюдения запись отбрасывается.
Так как описанная выше структура полностью описывает сводную таблицу, то задача ее визуализации будет тривиальна. При этом можно использовать стандартные компоненты таблицы, которые имеются практически во всех средствах программирования под Windows.
Первым продуктом, выполняющим OLAP-запросы, был Express (компания IRI). Однако, сам термин OLAP был предложен Эдгаром Коддом, «отцом реляционных БД». А работа Кодда финансировалась Arbor, компанией, выпустившей свой собственный OLAP-продукт - Essbase (позже купленный Hyperion, которая в 2007 г. была поглощена компанией Oracle) - годом ранее. Другие хорошо известные OLAP-продукты включают Microsoft Analysis Services (ранее называвшиеся OLAP Services, часть SQL Server), Oracle OLAP Option, DB2 OLAP Server от IBM (фактически, EssBase с дополнениями от IBM), SAP BW, продукты Brio, BusinessObjects, Cognos, MicroStrategy и других производителей.
C технической точки зрения, представленные на рынке продукты делятся на "физический OLAP" и "виртуальный". В первом случае наличествует программа, выполняющая предварительный расчет агрегатов, которые затем сохраняются в специальную многомерную БД, обеспечивающую быстрое извлечение. Примеры таких продуктов - Microsoft Analysis Services, Oracle OLAP Option, Oracle/Hyperion EssBase, Cognos PowerPlay. Во втором случае данные хранятся в реляционных СУБД, а агрегаты могут не существовать вообще или создаваться по первому запросу в СУБД или кэше аналитического ПО. Примеры таких продуктов - SAP BW, BusinessObjects, Microstrategy. Системы, имеющие в своей основе "физический OLAP" обеспечивают стабильно лучшее время отклика на запросы, чем системы "виртуальный OLAP". Поставщики систем "виртуальный OLAP" заявляют о большей масштабируемости их продуктов в плане поддержки очень больших объемов данных.
В настоящей работе мне хотелось бы подробнее рассмотреть продукт компании BaseGroup Labs - Deductor.
Deductor является аналитической платформой, т.е. основой для создания законченных прикладных решений. Реализованные в Deductor технологии позволяют на базе единой архитектуры пройти все этапы построения аналитической системы: от создания хранилища данных до автоматического подбора моделей и визуализации полученных результатов.
Состав системы:
Deductor Studio - аналитическое ядро платформы Deductor. В Deductor Studio включен полный набор механизмов, позволяющий получить информацию из произвольного источника данных, провести весь цикл обработки (очистка, трансформация данных, построение моделей), отобразить полученные результаты наиболее удобным образом (OLAP, таблицы, диаграммы, деревья решений...) и экспортировать результаты.
Deductor Viewer является рабочим местом конечного пользователя. Программа позволяет минимизировать требования к персоналу, т.к. все требуемые операции выполняются автоматически при помощи подготовленных ранее сценариев обработки, нет необходимости задумываться о способе получения данных и механизмах их обработки. Пользователю Deduсtor Viewer необходимо только выбрать интересующий отчет.
Deductor Warehouse - многомерное кросс-платформенное хранилище данных, аккумулирующее всю необходимую для анализа предметной области информацию. Использование единого хранилища позволяет обеспечить удобный доступ, высокую скорость обработки, непротиворечивость информации, централизованное хранение и автоматическую поддержку всего процесса анализа данных.
4. Client-Server
Deductor Server предназначен для удаленной аналитической обработки. Он предоставляет возможность как автоматически "прогонять" данные через существующие сценарии на сервере, так и переобучать имеющиеся модели. Использование Deductor Server позволяет реализовать полноценную трехзвенную архитектуру, в которой он выполняет функцию сервера приложений. Доступ к серверу обсепечивается при помощи Deductor Client.
Принципы работы:
1. Импорт данных
Анализ любой информации в Deductor начинается с импорта данных. В результате импорта данные приводятся к виду, пригодному для последующего анализа при помощи всех имеющихся в программе механизмов. Природа данных, формат, СУБД и прочее не имеют значения, т.к. механизмы работы со всеми унифицированы.
2. Экспорт данных
Наличие механизмов экспорта позволяет пересылать полученные результаты в сторонние приложения, например, передавать прогноз продаж в систему для формирования заказа на поставку или разместить подготовленный отчет на корпоративном web-сайте.
3. Обработка данных
Под обработкой в Deductor подразумевается любое действие, связанное с неким преобразованием данных, например, фильтрация, построение модели, очистка и прочее. Собственно в этом блоке и производятся самые важные с точки зрения анализа действия. Наиболее существенной особенностью механизмов обработки, реализованных в Deductor, является то, что полученные в результате обработки данные можно опять обрабатывать любым из доступных системе методов. Таким образом, можно строить сколь угодно сложные сценарии обработки.
4. Визуализация
Визуализировать данные в Deductor Studio (Viewer) можно на любом этапе обработки. Система самостоятельно определяет, каким способом она может это сделать, например, если будет обучена нейронная сеть, то помимо таблиц и диаграмм, можно просмотреть граф нейросети. Пользователю необходимо выбрать нужный вариант из списка и настроить несколько параметров.
5. Механизмы интеграции
В Deductor не предусмотрено средств ввода данных - платформа ориентирована исключительно на аналитическую обработку. Для использования информации, хранящейся в разнородных системах, предусмотрены гибкие механизмы импорта-экспорта. Взаимодействие может быть организовано при помощи пакетного выполнения, работы в режиме OLE сервера и обращения к Deductor Server.
6.Тиражирование знаний
Deductor позволяет реализовать одну из наиболее важных функций любой аналитической системы - поддержку процесса тиражирования знаний, т.е. обеспечение возможности сотрудникам, не разбирающимся в методиках анализа и способах получения того или иного результата, получать ответ на основе моделей подготовленных экспертом.
З аключение
В настоящей работе была рассмотрена такая область современных информационных технологий, как системы анализа данных. Проанализирован основной инструмент аналитической обработки информации - OLAP - технологии. Подробно раскрыта суть понятия OLAP и значение OLAP-систем в современном бизнес-процессе. Детально описана структура и процесс работы ROLAP-сервера. В качестве примера реализации данных OLAP - технологий приведена аналитическая платформа Deductor. Представляемая документация разработана и соответствует требованиям.
OLAP-технологии - это мощный инструмент обработки данных в реальном времени. OLAP-сервер позволяет организовывать и представлять данные в разрезе различных аналитических направлений и превращает данные в ценную информацию, которая помогает компаниям принимать более обоснованные решения.
Использование OLAP-систем обеспечивает стабильно высокий уровень производительности и масштабируемости, поддерживая объемы данных размером в несколько гигабайт, доступ к которым могут получить тысячи пользователей. С помощью OLAP-технологий доступ к информации осуществляется в реальном времени, т.е. обработка запросов теперь не замедляет процесс анализа, обеспечивая его оперативность и эффективность. Визуальные инструменты администрирования позволяют разрабатывать и внедрять даже самые сложные аналитические приложения, делая этот процесс простым и быстрым.
Подобные документы
Основа концепции OLAP (On-Line Analytical Processing) – оперативной аналитической обработки данных, особенности ее использования на клиенте и на сервере. Общие характеристика основных требования к OLAP-системам, а также способов хранения данных в них.
реферат , добавлен 12.10.2010
OLAP: общая характеристика, предназначение, цели, задачи. Классификация OLAP-продуктов. Принципы построения OLAP системы, библиотека компонентов CubeBase. Зависимость производительности клиентских и серверных OLAP-средств от увеличения объема данных.
курсовая работа , добавлен 25.12.2013
Вечное хранение данных. Сущность и значение средства OLAP (On-line Analytical Processing). Базы и хранилища данных, их характеристика. Структура, архитектура хранения данных, их поставщики. Несколько советов по повышению производительности OLAP-кубов.
контрольная работа , добавлен 23.10.2010
Построение систем анализа данных. Построение алгоритмов проектирования OLAP-куба и создание запросов к построенной сводной таблице. OLAP-технология многомерного анализа данных. Обеспечение пользователей информацией для принятия управленческих решений.
курсовая работа , добавлен 19.09.2008
Основные сведения об OLAP. Оперативная аналитическая обработка данных. Классификация продуктов OLAP. Требования к средствам оперативной аналитической обработки. Использование многомерных БД в системах оперативной аналитической обработки, их достоинства.
курсовая работа , добавлен 10.06.2011
Разработка подсистем анализа веб-сайта с помощью Microsoft Access и Olap-технологий. Теоретические аспекты разработки подсистемы анализа данных в информационной системе музыкального портала. Olap-технологии в подсистеме анализа объекта исследования.
курсовая работа , добавлен 06.11.2009
Рассмотрение OLAP-средств: классификация витрин и хранилищ информации, понятие куба данных. Архитектура системы поддержки принятия решений. Программная реализация системы "Abitura". Создание Web-отчета с использованием технологий Reporting Services.
курсовая работа , добавлен 05.12.2012
Хранилище данных, принципы организации. Процессы работы с данными. OLAP-структура, технические аспекты многомерного хранения данных. Integration Services, заполнение хранилищ и витрин данных. Возможности систем с использованием технологий Microsoft.
курсовая работа , добавлен 05.12.2012
Построение схемы хранилища данных торгового предприятия. Описания схем отношений хранилища. Отображение информации о товаре. Создание OLAP-куба для дальнейшего анализа информации. Разработка запросов, позволяющих оценить эффективность работы супермаркета.
контрольная работа , добавлен 19.12.2015
Назначение хранилищ данных. Архитектура SAP BW. Построение аналитической отчетности на основе OLAP-кубов в системе SAP BW. Основные различия между хранилищем данных и системой OLTP. Обзор функциональных сфер BEx. Создание запроса в BEx Query Designer.