V computer systems under synchronous input and synchronous output understand the processes of input-output of data samples, in which the time intervals (frequency) of the transfer of samples to input or output are clearly stored. I / O synchronization is provided with the help of one or another hardware support (timers and various other peripheral devices with synchronization means and using data buffering to align the I / O data stream). Moreover, the term synchronous I / O does not necessarily mean that the I / O interface has a sync signal, and synchronicity can be provided by both internal and external synchronization.
Usually, in processor and measuring systems, the direction of the data flow (to input or output) is considered relative to the computer (processor) at the center of the architecture under consideration. In particular, the readings of the ADC and digital (discrete) inputs are considered data for input, and the readings of the DAC and digital (control) outputs are considered data for the output.
At asynchronous input and output the time intervals (periodicity) of the transfer of samples to input or output are not saved. At the same time, data arrives at the input or output at the rate of the data transfer interface itself, with unpredictable buffering delays, without saving any time intervals. In particular, this means for the programmer that when using asynchronous I / O functions, it makes no sense to compare the moments of calling the asynchronous I / O function with the physical moments of the execution of this operation “on the other side of the interface” (such a comparison makes sense only with a statistical method of data processing) ... The fact of an asynchronous output operation can be verified by confirmation (if this output operation has confirmation, or confirmation can be obtained by a subsequent data input operation). With asynchronous I / O, the above data buffering can play the opposite role and increase the uncertainty of data delivery time in the absence of a mechanism for synchronization and traffic control of data transmission.
ADC / DAC module
16/32 channels, 16 bit, 2 MHz, USB, Ethernet
The task that issued the I / O request is placed by the supervisor in a state waiting for the ordered operation to complete. When the supervisor receives a message from the completion section that the operation has completed, he puts the task in a ready-to-run state, and it continues its work. This situation corresponds to synchronous I / O. Synchronous I / O is standard on most operating systems. To speed up the execution of applications, it has been suggested to use asynchronous I / O if necessary.
The simplest variant of asynchronous output is the so-called buffered output of data to an external device, in which data from the application is transferred not directly to the input / output device, but to a special system buffer. In this case, logically, the output operation for the application is considered completed immediately, and the task may not wait for the end of the actual process of transferring data to the device. The actual output of data from the system buffer is handled by the I / O supervisor. Naturally, the allocation of the buffer from the system memory area is handled by a special system process at the direction of the I / O supervisor. So, for the considered case, the output will be asynchronous if, firstly, the I / O request indicated the need to buffer data, and secondly, if the I / O device allows such asynchronous operations and this is noted in the UCB. You can organize and asynchronous data entry. However, to do this, it is necessary not only to allocate a memory area for temporary storage of data read from the device and to associate the allocated buffer with the task that ordered the operation, but also to split the I / O request itself into two parts (into two requests). The first request specifies the operation to read data, similar to how it is done with synchronous I / O. However, the type (code) of the request is used differently, and the request specifies at least one additional parameter - the name (code) of the system object that the task receives in response to the request and which identifies the allocated buffer. Having received the name of the buffer (we will conventionally call this system object in this way, although other terms are used for its designation in various operating systems, for example, a class), the task continues its work. It is very important to emphasize here that as a result of an asynchronous input request, the task is not placed by the I / O supervisor in a state waiting for an I / O operation to complete, but remains in an executing or ready-to-execute state. After some time, after executing the necessary code, which was determined by the programmer, the task issues a second request to complete the I / O operation. In this second request to the same device, which, of course, has a different code (or request name), the task specifies the name of the system object (buffer for asynchronous data input) and, if the read operation completes successfully, it immediately receives it from the system buffer. If the data has not yet been fully written from the external device to the system buffer, the I / O supervisor puts the task in the state of waiting for the completion of the I / O operation, and then everything resembles normal synchronous data input.
Typically, asynchronous I / O is provided in most multiprogramming operating systems, especially if the operating system supports multitasking using a threading mechanism. However, if there is no explicit asynchronous I / O, you can implement its ideas yourself by organizing a separate stream for data output.
I / O hardware can be viewed as a collection of hardware processors, which are able to work in parallel with respect to each other, as well as with respect to the central processor (s). On such "processors" the so-called external processes. For example, for an external device (input / output device), the external process can be a set of operations that move the print head, advance the paper one position, change the ink color, or print some characters. External processes, using input / output equipment, interact both with each other and with ordinary "software" processes running on the central processor. In this case, it is important that the speed of execution of external processes will differ significantly (sometimes, by an order of magnitude or more) from the speed of execution of ordinary (" internal») Processes. For their normal operation, external and internal processes must be synchronized. To smooth out the effect of a strong speed mismatch between internal and external processes, the aforementioned buffering is used. Thus, we can talk about a system of parallel interacting processes (see Chapter 6).
Buffers are a critical resource in relation to internal (software) and external processes, which interact informationally during their parallel development. Through the buffer (buffers), data is either sent from some process to an addressable external one (operation of outputting data to an external device), or from an external process is transferred to some program process (data reading operation). The introduction of buffering as a means of information interaction raises the problem of managing these system buffers, which is solved by means of the supervisory part of the OS. In this case, the supervisor is entrusted with the tasks of not only allocating and freeing buffers in the system memory area, but also synchronizing processes in accordance with the state of operations for filling or freeing buffers, as well as waiting for them if there are no free buffers available, and the request for input / the output requires buffering. Typically, the I / O supervisor uses the standard synchronization tools adopted in this OS to solve the listed tasks. Therefore, if the OS has developed tools for solving the problems of parallel execution of interacting applications and tasks, then, as a rule, it also implements asynchronous I / O.
Input and output operations are inherently slower than other types of processing. The reasons for this slowdown are the following factors:
Delays caused by the time spent searching for the desired tracks and sectors on random access devices (disks, CDs).
Latency due to the relatively slow data exchange rate between physical devices and system memory.
Delays in transferring data over the network using file, servers, data warehouses, and so on.
In all the previous examples, I / O operations are performed synchronous with the stream, therefore, the entire thread is forced to stand idle until they complete.
This chapter shows you how you can arrange for a thread to continue executing without waiting for I / O to complete, which will match the execution of threads. asynchronous input / output. The various techniques available in Windows are illustrated with examples.
Some of these techniques are used in wait timers, which are also described in this chapter.
Finally, and most importantly, by examining standard asynchronous I / O operations, we can use I / O completion ports, which are extremely useful when building scalable servers that can support a large number of clients without creating a separate thread for each client. Program 14.4 is a modified version of a previously developed server that allows the use of I / O completion ports.
Overview of Windows Asynchronous I / O Methods
Windows provides three techniques for performing asynchronous I / O.
Multihreaded I / O. Each of the threads within a process or set of processes performs normal synchronous I / O, but other threads can continue to execute.
Overlapped I / O After starting a read, write, or other I / O operation, the stream continues its execution. If a thread requires I / O to continue executing, it waits until the appropriate handle becomes available or the specified event occurs. In Windows 9x, overlapping I / O is only supported for serial devices such as named pipes.
Completion routines (extended I / O). When I / O is complete, the system calls a special completion procedure, running inside the thread. Extended I / O for disk files is not supported in Windows 9x.
Multithreaded I / O using named pipes is used in the multithreaded server discussed in Chapter 11. The grepMT program (Program 7.1) handles concurrent I / O operations involving multiple files. Thus, we already have a number of programs that perform multithreaded I / O and thus provide one form of asynchronous I / O.
Overlapping I / O is the subject of the next section, and the ASCII to UNICODE file conversion examples in the section use this technique to illustrate the sequential processing of files. For this purpose, a modified version of the program 2.4 is used. Overlapping I / O is followed by extended I / O using completion routines.
Note
Overlapping and extended I / O methods are often difficult to implement, rarely provide any performance benefits, sometimes even cause performance degradation, and in the case of file I / O, they can only work under Windows control NT. These problems are overcome with streams, so many readers will probably want to skip straight to the sections on wait timers and I / O completion ports, returning to this section as needed. On the other hand, the elements of asynchronous I / O are present in both legacy and new technologies, so these methods are still worth learning.
So, the COM technology on the NT5 platform supports asynchronous method invocation, so this technique can be useful to many readers who use or are going to use the COM technology. In addition, asynchronous procedure call operations (Chapter 10) have a lot in common with extended I / O, and although I personally prefer to use streams, others may prefer this mechanism.
Overlapping I / O
The first thing to do to organize asynchronous I / O, whether overlapped or extended, is to set the overlapped attribute on a file or other descriptor. To do this, when calling CreateFile or any other function that creates a file, named pipe, or other descriptor, specify the FILE_FLAG_OVERLAPPED flag.
In the case of sockets (Chapter 12), regardless of whether they were created using the socket or accept function, the overlap attribute is set by default in Winsock 1.1, but must be set explicitly in Winsock 2.0. Overlapping sockets can be used asynchronously on all versions of Windows.
Up to this point, OVERLAPPED structures have been used in conjunction with the LockFileEx function, as well as as an alternative to using the SetFilePointer function (Chapter 3), but they are also an essential element of overlapping I / O. These structures act as optional parameters when calling the four functions below, which can block on completion of operations.
Recall that when FILE_FLAG_OVERLAPPED is specified in the dwAttrsAndFlags parameter (for the CreateFile function) or the dwOpen-Mode parameter (for the CreateNamedPipe function), the corresponding file or pipe can only be used in overlap mode. Overlapping I / O does not work with anonymous pipes.
Note
There is a mention in the documentation for the CreateFile function that using the FILE_FLAG_NO_BUFFERING flag improves the performance of overlapped I / O. Experiments show only marginal performance gains (about 15%, which can be verified by experimenting with Program 14.1), but you must ensure that the total size of the data read during the ReadFile or WriteFile operation is a multiple of the disk sector size.
Overlapping sockets
One of the most important innovations in Windows Sockets 2.0 (Chapter 12) is the standardization of overlapping I / O. In particular, sockets are no longer automatically created as overlapped file descriptors. The socket function creates a non-overlapping handle. To create an overlapping socket, call the WSASocket function explicitly requesting the creation of an overlapping tip by specifying the WSA_FLAG_OVERLAPPED value for the dwFlags parameter of the WSASocket function.
SOCKET WSAAPI WSASocket (int iAddressFamily, int iSocketType, int iProtocol, LPWSAPROTOCOL_INFO lpProtocolInfo, GROUP g, DWORD dwFlags);
To create a socket, use the WSASocket function instead of the socket function. Any socket returned by accept will have the same properties as the argument.
Consequences of Using Overlapped I / O
Overlapping I / O is performed asynchronously. This has several consequences.
Overlapping I / O operations are not blocked. The ReadFile, WriteFile, TransactNamedPipe, and ConnectNamedPipe functions return without waiting for the I / O operation to complete.
The return value of the function cannot be used as a criterion for the success or failure of its execution, since the I / O operation has not yet completed yet. A different mechanism is required to indicate the status of I / O progress.
The return value of the number of bytes transferred is also of little use, since the data transfer might not be complete. Windows must provide a different mechanism to get this kind of information.
A program can make multiple attempts to read or write using the same overlapping file descriptor. Therefore, the file pointer corresponding to such a descriptor is also insignificant. Therefore, an additional method must be provided to ensure that the file position is specified for each read or write operation. In the case of named pipes, due to their inherent sequential nature of data processing, this is not a problem.
The program must be able to wait (synchronize) for I / O completion. If there are multiple pending I / O operations associated with the same handle, the program should be able to determine which operations have already completed. I / O operations do not necessarily end in the same order in which they started.
To overcome the last two of the difficulties listed above, OVERLAPPED structures are used.
OVERLAPPED Structures
The following information can be specified using the OVERLAPPED structure (specified, for example, by the lpOverlapped parameter of the ReadFile function):
The position in the file (64 bits) at which to start a read or write operation, as discussed in Chapter 3.
An event (manually cleared) that will transition to a signaled state when the corresponding operation completes.
Following is the definition of the OVERLAPPED structure.
Both the Offset and OffsetHigh fields should be used to set the position in the file (the pointer), although the upper part of the pointer (OffsetHigh) is in many cases 0. Do not use the Internal and InternalHigh fields, which are reserved for system needs.
The hEvent parameter is a handle to the event (created by the CreateEvent function). This event can be named or unnamed, but it must must be manually resettable (see Chapter 8) if used for overlapping I / O; the reasons for this will be explained shortly. Upon completion of the I / O operation, the event becomes signaled.
In another possible use, the hEvent descriptor is NULL; in this case, the program can wait for a transition to the signal state of the file descriptor, which can also act as a synchronization object (see the following caveats). The system uses the signal states of the file descriptor to track the completion of operations if the hEvent descriptor is NULL, that is, the synchronization object in this case is the file descriptor.
Note
For convenience's sake, the term "file handle", used in relation to descriptors specified when calling ReadFile, WriteFile, and so on, will be used by us even when it comes to named pipe or device descriptors. not a file.
When an I / O function call is made, this event is immediately cleared by the system (set to a non-signaled state). When the I / O operation completes, the event is signaled and remains signaled until consumed by another I / O operation. An event should be manually reset if multiple threads can wait for it to signalize (although our examples use only one thread), and they may not be waiting when the operation completes.
Even if the file descriptor is synchronous (that is, created without the FILE_FLAG_OVERLAPPED flag), the OVERLAPPED structure can serve as an alternative to the SetFilePointer function to specify the position in the file. In this case, no return after calling ReadFile or any other call occurs until the I / O operation completes. We have already used this feature in Chapter 3. Also note that pending I / O operations are uniquely identified by the combination of a file descriptor and a corresponding OVERLAPPED structure.
Listed below are some of the cautions you should take into account.
Do not reuse the OVERLAPPED structure while the associated I / O operation, if any, has not yet completed.
Likewise, avoid reusing the event specified in the OVERLAPPED structure.
If there are multiple pending requests for the same overlapping descriptor, use event descriptors instead of file descriptors for synchronization.
If the OVERLAPPED structure or event acts as automatic variables within a block, ensure that the block cannot be exited before synchronizing with the I / O operation. In addition, to avoid resource leakage, care should be taken to close the handle before exiting the block.
Overlapping I / O States
Returns from the ReadFile and WriteFile functions, as well as the above two named pipe functions, when they are used to perform overlapping I / O operations, return immediately. In most cases, the I / O operation will not have completed by this time, and the return value for read and write will be FALSE. The GetLastError function will return ERROR_IO_PENDING in this situation.
After you have finished waiting for the sync object (event, or possibly a file descriptor) to signalize that the operation is complete, you should figure out how many bytes were transferred. This is the main purpose of the GetOverlappedResult function.
BOOL GetOverlappedResult (HANDLE hFile, LPOVERLAPPED lpOverlapped, LPWORD lpcbTransfer, BOOL bWait)
Specifying a specific I / O operation is provided by a combination of a handle and an OVERLAPPED structure. If bWait is TRUE, the GetOverlappedResult function must wait until the operation completes; otherwise, the return from the function must be immediate. In any case, this function will return TRUE only after the operation has completed successfully. If the return value of the GetOverlappedResult function is FALSE, then the GetLastError function will return ERROR_IO_INCOMPLETE, which allows this function to be called to poll for I / O completion.
The number of bytes transferred is stored in the * lpcbTransfer variable. Always ensure that the OVERLAPPED structure remains unchanged from the time it is used in an overlapping I / O operation.
Canceling Overlapping I / O Operations
The Boolean function CancelIO allows you to cancel pending overlapping I / O operations associated with the specified handle (this function has only one parameter). Cancels the execution of all operations initiated by the calling thread that use the given handle. Calls to this function have no effect on operations initiated by other threads. Canceled operations end with ERROR OPERATION ABORTED.
Example: Using a File Descriptor as a Synchronization Object
Overlapping I / O is very convenient and easy to implement in cases where there can be only one pending operation. Then, for synchronization purposes, the program can use not an event, but a file descriptor.
The following code snippet shows how a program can initiate a read operation to read a portion of a file, continue execution for other processing, and then go into a state of waiting for the file descriptor to go signaled.
OVERLAPPED ov = (0, 0, 0, 0, NULL / * Events are not used. * /);
hF = CreateFile (..., FILE_FLAG_OVERLAPPED, ...);
ReadFile (hF, Buffer, sizeof (Buffer), & nRead, & ov);
/ * Do other processing. nRead is not necessarily reliable. * /
/ * Wait for the read operation to complete. * /
WaitForSingleObject (hF, INFINITE);
GetOverlappedResult (hF, & ov, & nRead, FALSE);
Example: Converting Files Using Overlapping I / O and Multiple Buffering
Program 2.4 (atou) converted an ASCII file to UNICODE by processing the file sequentially, and Chapter 5 showed you how to do the same sequential processing by displaying files. Program 14.1 (atouOV) accomplishes the same task using overlapping I / O and multiple buffers that hold fixed-size records.
Figure 14.1 illustrates the organization of a program with four fixed-size buffers. The program is implemented in such a way that the number of buffers can be determined using a symbolic preprocessor constant, but in the following discussion, we will assume that there are four buffers.
First, the program initializes all elements of the OVERLAPPED structures that define events and positions in files. A separate OVERLAPPED structure is provided for each input and output buffers. An overlapping read operation is then initiated for each of the input buffers. Next, using the WaitForMultipleObjects function, the program waits for a single event indicating the completion of a read or write. When the read operation completes, the input buffer is copied and converted to the corresponding output buffer, after which the write operation is initiated. When the write completes, the next read operation is initiated. Note that events related to input and output buffers are placed in a single array, which is used as an argument when calling the WaitForMultipleObjects function.
Rice. 14.1. Asynchronous file update model
Program 14.1. atouOV: converting a file using overlapping I / O
Convert a file from ASCII to Unicode using overlapping I / O. The program only works in Windows NT. * /
#define MAX_OVRLP 4 / * Number of overlapping I / O operations. * /
#define REC_SIZE 0x8000 / * 32 KB: The minimum record size for acceptable performance. * /
/ * Each of the elements of the variable arrays defined below * /
/ * and structures matches a single pending operation * /
/ * overlapping I / O. * /
DWORD nin, nout, ic, i;
OVERLAPPED OverLapIn, OverLapOut;
/ * The need to use a solid, two-dimensional array * /
/ * dictated by the WaitForMultipleObjects Function. * /
/ * A value of 0 for the first index corresponds to reading, a value of 1 - writing. * /
/ * In each of the two buffer arrays defined below, the first index is * /
/ * numbers the input / output operations. * /
LARGE_INTEGER CurPosIn, CurPosOut, FileSize;
/ * Total number of records to be processed, calculated * /
/ * based on the size of the input file. End entry * /
/ * may be incomplete. * /
for (ic = 0; ic< MAX_OVRLP; ic++) {
/ * Create read and write events for each OVERLAPPED structure. * /
hEvents = OverLapIn.hEvent / * Read event. * /
hEvents = OverLapOut.hEvent / * Recording event. * /
= CreateEvent (NULL, TRUE, FALSE, NULL);
/ * Starting positions in the file for each OVERLAPPED structure. * /
/ * Initiate an overlapping read operation for this OVERLAPPED structure. * /
if (CurPosIn.QuadPart< FileSize.QuadPart) ReadFile(hInputFile, AsRec, REC_SIZE, &nin, &OverLapIn);
/ * All read operations are performed. Wait for the event to complete and discard it immediately. Read and write events are stored in an array of events next to each other. * /
iWaits = 0; / * The number of I / O operations performed so far. * /
while (iWaits< 2 * nRecord) {
ic = WaitForMultipleObjects (2 * MAX_OVRLP, hEvents, FALSE, INFINITE) - WAIT_OBJECT_0;
iWaits ++; / * Increment the counter of completed I / O operations. * /
ResetEvent (hEvents);
/ * Reading completed. * /
GetOverlappedResult (hInputFile, & OverLapIn, & nin, FALSE);
for (i = 0; i< REC_SIZE; i++) UnRec[i] = AsRec[i];
WriteFile (hOutputFile, UnRec, nin * 2, & nout, & OverLapOut);
/ * Prepare for the next read, which will be initiated after the write operation started above is completed. * /
OverLapIn.Offset = CurPosIn.LowPart;
OverLapIn.OffsetHigh = CurPosIn.HighPart;
) else if (ic< 2 * MAX_OVRLP) { /* Операция записи завершилась. */
/ * Start reading. * /
ic - = MAX_OVRLP; / * Set the index of the output buffer. * /
if (! GetOverlappedResult (hOutputFile, & OverLapOut, & nout, FALSE)) ReportError (_T ("Read error."), 0, TRUE);
CurPosIn.LowPart = OverLapIn.Offset;
CurPosIn.HighPart = OverLapIn.OffsetHigh;
if (CurPosIn.QuadPart< FileSize.QuadPart) {
/ * Start a new read operation. * /
ReadFile (hInputFile, AsRec, REC_SIZE, & nin, & OverLapIn);
/ * Close all events. * /
for (ic = 0; ic< MAX_OVRLP; ic++) {
Program 14.1 can only run under Windows NT. Windows 9x Asynchronous I / O does not allow the use of disk files. Appendix B contains results and comments showing the comparatively poor performance of the atouOV program. Experiments have shown that the buffer size should be at least 32K to achieve acceptable performance, but even so, normal synchronous I / O is faster. In addition, the performance of this program does not increase under SMP conditions, since in this example where only two files are processed, the CPU is not a critical resource.
Advanced I / O using a completion routine
There is also another possible approach to using synchronization objects. Rather than forcing a thread to wait for a completion signal from an event or handle, the system can initiate a user-defined completion routine call as soon as the I / O operation completes. The completion routine can then start another I / O operation and take any necessary steps to account for the use of system resources. This callback completion routine is similar to the asynchronous routine call used in Chapter 10 and requires alertable wait states.
How can a termination procedure be specified in a program? There are no parameters or data structures for the ReadFile and WriteFile functions that can be used to store the address of the completion routine. However, there is a family of extended I / O functions that are denoted by the "Ex" suffix and contain an additional parameter to convey the address of the termination routine. The read and write functions are ReadFileEx and WriteFileEx, respectively. In addition, one of the following standby functions is required.
Advanced I / O is sometimes called duty input / output(alertable I / O). How to use advanced features is described in the following sections.
Note
Under Windows 9x, extended I / O cannot handle disk files and communication ports. At the same time, Windows 9x extended I / O is capable of working with named pipes, mailboxes, sockets, and serial devices.
ReadFileEx, WriteFileEx Functions, and Completion Routines
Extended read and write functions can be used in conjunction with open file, named pipe, and mailbox descriptors if the corresponding object was opened (created) with the FILE_FLAG_OVERLAPPED flag set. Note that this flag sets the attribute of the descriptor, and although overlapping and extended I / O are different, the same flag applies to descriptors of both types of asynchronous I / O.
Overlapping sockets (Chapter 12) can be used in conjunction with the ReadFileEx and WriteFileEx functions on all versions of Windows.
BOOL ReadFileEx (HANDLE hFile, LPVOID lpBuffer, DWORD nNumberOfBytesToRead, LPOVERLAPPED lpOverlapped, LPOVERLAPPED_COMPLETION_ROUTINE lpcr)BOOL WriteFileEx (HANDLE hFile, LPVOID lpBuffer, DWORD nNumberOfBytesToWrite, LPOVERLAPPED lpOverlapped, LPOVERLAPPED_COMPLETION_ROUTINE lpcr)
You are already familiar with both functions, except that each of them has an additional parameter that allows you to specify the address of the termination routine.
Each of the functions needs to provide an OVERLAPPED structure, but there is no need to specify the hEvent member of that structure; the system ignores it. However, this element is very useful for conveying information such as a sequence number used to distinguish between individual I / O operations, as shown in Program 14.2.
Comparing with the ReadFile and WriteFile functions, you will notice that the extended functions do not require parameters to store the number of bytes transferred. This information is passed to the completion function, which must be included in the program.
The completion function provides parameters for the byte count, error code, and address of the OVERLAPPED structure. The last of the named parameters is required so that the termination routine can determine which of the outstanding operations completed. Note that the previous caveats about reusing or destroying OVERLAPPED structures are just as true here as they are for overlapping I / O.
VOID WINAPI FileIOCompletionRoutine(DWORD dwError, DWORD cbTransferred, LPOVERLAPPED lpo)
As in the case of the CreateThread function, the call of which also specifies the name of some function, the name FileIOCompletionRoutine is a placeholder, not the actual name of the completion routine.
The dwError parameter values are limited to 0 (success) and ERROR_HANDLE_EOF (when trying to read out of bounds of the file). The OVERLAPPED structure is the one used by the resulting call to ReadFileEx or WriteFileEx.
Before the termination routine is called by the system, two things must happen:
1. The I / O operation should complete.
2. The calling thread must be in a standby state, notifying the system to execute a queued termination routine.
How does a thread go into a standby state? It must make an explicit call to one of the watchdog functions described in the next section. Thus, the thread creates conditions that make it impossible for the termination routine to execute prematurely. A thread can be in the standby state only as long as the call to the standby function lasts; after returning from this function, the thread exits the specified state.
If both of these conditions are met, the completion routines that have been queued as a result of I / O completion are executed. Completion routines run on the same thread that made the original I / O function call and is in a standby state. Therefore, a thread should only enter the standby state when safe conditions exist to execute the termination routines.
Standby functions
There are five standby functions in total, but below are prototypes of only three of them that are of immediate interest to us:
DWORD WaitForSingleObjectEx (HANDLE hObject, DWORD dwMilliseconds, BOOL bAlertable)DWORD WaitForMultipleObjectsEx (DWORD cObjects, LPHANDLE lphObjects, BOOL fWaitAll, DWORD dwMilliseconds, BOOL bAlertable)DWORD SleepEx (DWORD dwMilliseconds, BOOL bAlertable)
Each of the watchdog functions has a bAlertable flag that must be set to TRUE for asynchronous I / O. The above functions are extensions of the familiar Wait and Sleep functions.
The duration of the wait intervals is indicated, as usual, in milliseconds. Each of these three functions returns as soon as any of the following situations:
The descriptor (s) is (are) signaled to satisfy the standard requirements of two of the wait functions.
Timeout expires.
All terminators in the thread's queue are terminated and bAlertable is TRUE. The completion routine is queued when the corresponding I / O operation completes (Figure 14.2).
Note that there are no events associated with the OVERLAPPED structures in the ReadFileEx and WriteFileEx functions, so none of the descriptors specified when calling the wait function are associated directly with any specific I / O operation. At the same time, the SleepEx function is not related to synchronization objects, and therefore the easiest to use. In the case of the SleepEx function, the length of the sleep interval is usually INFINITE, so this function will return only after one or more of the terminators that are currently in the queue have finished executing.
Execute the termination procedure and return from the standby function
When the extended I / O operation completes, its associated completion routine, with its arguments defining the OVERLAPPED structure, byte count, and error code, is queued for execution.
Any termination routines in the thread's queue begin executing when the thread enters the standby state. They are executed one at a time, but not necessarily in the same sequence in which the I / O operations completed. The return from the standby function occurs only after the completion routine returns. This is important to keep in mind for most programs to function properly because it assumes that the termination routines are able to prepare for the next use of the OVERLAPPED structure and perform other necessary actions to bring the program to a known state before returning from the standby state.
If the return from the SleepEx function is due to the execution of one or more queued completion procedures, then the return value of the function will be WAIT_TO_COMPLETION, and the same value will be returned by the GetLastError function called after one of the wait functions returns.
In conclusion, we note two points:
1. When calling any of the watchdog functions, use INFINITE as the timeout parameter value. In the absence of the possibility of expiration of the waiting interval, the return from the functions will be carried out only after the execution of all completion procedures is completed or the descriptors go into the signal state.
2. It is common to use the hEvent data member of the OVERLAPPED structure to pass information to the termination routine, since this field is ignored by the OS.
Figure 2 illustrates the interaction between the main thread, termination routines, and watchdog functions. 14.2. This example starts three concurrent read operations, two of which complete by the time the watchdog starts.
Rice. 14.2. Asynchronous I / O Using Completion Routines
Example: converting a file using extended I / O
Program 14.3 (atouEX) is a revised version of program 14.1. These programs illustrate the difference between the two asynchronous I / O methods. The atouEx program is similar to Program 14.1, but it moves most of the resource ordering code into the finalizer, and makes many variables global so that the finalizer can access them. However, Appendix B shows that in terms of performance, atouEx may well compete with other methods that do not use file mapping, while atouOV is slower.
Program 14.2. atouEx: converting a file using extended I / OConvert a file from ASCII to Unicode using EXPANDED I / O. * /
/ * atouEX file1 file2 * /
#define REC_SIZE 8096 / * The block size is not as important in terms of performance as in the case of atouOV. * /
#define UREC_SIZE 2 * REC_SIZE
static VOID WINAPI ReadDone (DWORD, DWORD, LPOVERLAPPED);
static VOID WINAPI WriteDone (DWORD, DWORD, LPOVERLAPPED);
/ * The first OVERLAPPED structure is for reading, and the second for writing. Structures and buffers are allocated for each pending operation. * /
OVERLAPPED OverLapIn, OverLapOut;
CHAR AsRec;
WCHAR UnRec;
HANDLE hInputFile, hOutputFile;
int _tmain (int argc, LPTSTR argv) (
hInputFile = CreateFile (argv, GENERIC_READ, 0, NULL, OPEN_EXISTING, FILE_FLAG_OVERLAPPED, NULL);
hOutputFile = CreateFile (argv, GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, FILE_FLAG_OVERLAPPED, NULL);
FileSize.LowPart = GetFileSize (hInputFile, & FileSize.HighPart);
nRecord = FileSize.QuadPart / REC_SIZE;
if ((FileSize.QuadPart% REC_SIZE)! = 0) nRecord ++;
for (ic = 0; ic< MAX_OVRLP; ic++) {
OverLapIn.hEvent = (HANDLE) ic; / * Reload event. * /
OverLapOut.hEvent = (HANDLE) ic; / * Fields. * /
OverLapIn.Offset = CurPosIn.LowPart;
OverLapIn.OffsetHigh = CurPosIn.HighPart;
if (CurPosIn.QuadPart< FileSize.QuadPart) ReadFileEx(hInputFile, AsRec, REC_SIZE, &OverLapIn , ReadDone);
CurPosIn.QuadPart + = (LONGLONG) REC_SIZE;
/ * All read operations are performed. Enter the standby state and stay in it until all records have been processed. * /
while (nDone< 2 * nRecord) SleepEx(INFINITE, TRUE);
_tprintf (_T ("Conversion from ASCII to Unicode completed. \ n"));
static VOID WINAPI ReadDone (DWORD Code, DWORD nBytes, LPOVERLAPPED pOv) (
/ * Reading completed. Convert data and initiate recording. * /
LARGE_INTEGER CurPosIn, CurPosOut;
/ * Process the write and initiate the write operation. * /
CurPosIn.LowPart = OverLapIn.Offset;
CurPosIn.HighPart = OverLapIn.OffsetHigh;
CurPosOut.QuadPart = (CurPosIn.QuadPart / REC_SIZE) * UREC_SIZE;
OverLapOut.Offset = CurPosOut.LowPart;
OverLapOut.OffsetHigh = CurPosOut.HighPart;
/ * Convert notation from ASCII to Unicode. * /
for (i = 0; i< nBytes; i++) UnRec[i] = AsRec[i];
WriteFileEx (hOutputFile, UnRec, nBytes * 2, & OverLapOut, WriteDone);
/ * Prepare the OVERLAPPED structure for next reading. * /
CurPosIn.QuadPart + = REC_SIZE * (LONGLONG) (MAX_OVRLP);
OverLapIn.Offset = CurPosIn.LowPart;
OverLapIn.OffsetHigh = CurPosIn.HighPart;
static VOID WINAPI WriteDone (DWORD Code, DWORD nBytes, LPOVERLAPPED pOv) (
/ * Writing completed. Initiate the next read operation. * /
CurPosIn.LowPart = OverLapIn.Offset;
CurPosIn.HighPart = OverLapIn.OffsetHigh;
if (CurPosIn.QuadPart< FileSize.QuadPart) {
ReadFileEx (hInputFile, AsRec, REC_SIZE, & OverLapIn, ReadDone);
Asynchronous I / O using multiple threads
Overlapping and extended I / O allows for asynchronous I / O within a single thread, although the OS creates its own threads to support this functionality. Methods of this type are often used in one form or another in many early operating systems to support limited forms of asynchronous operations on single-threaded systems.
However, Windows provides multithreading support, so it becomes possible to achieve the same effect by performing synchronous I / O on multiple, independently executing threads. We've previously demonstrated these capabilities with multithreaded servers and grepMT (Chapter 7). In addition, streams provide a conceptually sequential and, presumably much simpler, way to perform asynchronous I / O operations. As an alternative to the methods used in Programs 14.1 and 14.2, one could provide each thread with its own file descriptor, and then each of the threads could process every fourth record synchronously.
This way of using streams is demonstrated in the atouMT program, which is not included in the book but is included in the material on the Web site. Not only can atouMT run on any version of Windows, but it is simpler than either of the two asynchronous I / O programs because it is less complex to account for resource usage. Each thread simply maintains its own buffers on its own stack and performs a sequence of synchronous reads, conversions, and writes in a loop. At the same time, the performance of the program remains at a sufficient high level.
Note
The atouMT.c program on the Web site comments on several possible pitfalls that may lie in wait for multiple threads accessing the same file at the same time. In particular, all individual file descriptors must be created using the CreateHandle function, not the DuplicateHandle function.
Personally, I prefer to use multi-threaded file processing over asynchronous I / O operations. Streams are easier to program and provide better performance in most cases.
There are two exceptions to this general rule. The first, as shown earlier in this chapter, deals with situations in which there can be only one outstanding operation, and a file descriptor can be used for synchronization purposes. A second and more important exception occurs in the case of asynchronous I / O completion ports, which will be discussed at the end of this chapter.
Wait Timers
Windows NT supports waitable timers, which are a type of kernel object that waits.
You can always create your own sync signal by creating a sync thread that raises an event when it wakes up after a call to the Sleep function. In serverNP Program 11.3, the server also uses a clock stream to periodically broadcast its channel name. Therefore, wait timers provide, although somewhat redundant, a convenient way to organize the execution of tasks on a periodic basis or in accordance with a specific schedule. In particular, the wait timer can be configured so that the signal is generated at a specific time.
The wait timer can be either a synchronization timer or a manual-reset notification timer. The synchronization timer is associated with an indirect call function similar to the extended I / O completion procedure, while the wait function is used to synchronize with a manually reset notifying timer.
First, you need to create a timer descriptor using the CreateWaitableTimer function.
HANDLE CreateWaitableTimer (LPSECURITY_ATTRIBUTES lpTimerAttributes, BOOL bManualReset, LPCTSTR lpTimerName);
The second parameter, bManualReset, determines which type of timer should be created - synchronization or notification. Program 14.3 uses a sync timer, but by changing the comments and setting a parameter, you can easily turn it into a notification timer. Note that there is also an OpenWaitableTimer function that can use the optional name provided by the third argument.
Initially, the timer is created in an inactive state, but using the SetWaitableTimer function, you can activate it and specify the initial time delay, as well as the duration of the time interval between periodically generated signals.
BOOL SetWaitableTimer (HANDLE hTimer, const LARGE_INTEGER * pDueTime, LONG IPeriod, PTIMERAPCROUTINE pfnCompletionRoutine, LPVOID lpArgToCompletionRoutine, BOOL fResume);
hTimer is a valid handle to the timer created using the CreateWaitableTimer function.
The second parameter, pointed to by the pDueTime pointer, can be either positive values corresponding to absolute time, or negative values corresponding to relative time, with actual values expressed in units of time of 100 nanoseconds, and their format described by the FILETIME structure. Variables of type FILETIME were introduced in Chapter 3 and have already been used by us in Chapter 6 in the timep program (Program 6.2).
The interval between signals, specified in the third parameter, is expressed in milliseconds. If this value is set to 0, the timer is signaled only once. With positive values of this parameter, the timer is periodic and fires periodically until its action is terminated by a call to the CancelWaitableTimer function. Negative values for the specified interval are not allowed.
The fourth parameter, pfnCompletionRoutine, applies in the case of a sync timer and specifies the address of the completion routine that is called when the timer enters the signaled state. and provided that the thread enters the standby state. When this procedure is called, the pointer specified by the fifth parameter, plArgToComplretionRoutine, is used as one of the arguments.
After setting a sync timer, you can put the thread on standby by calling the SleepEx function to enable the termination routine to be called. In the case of a manually-resettable notifying timer, wait for the timer descriptor to transition to the signaled state. The descriptor will remain signaled until the next call to the SetWaitableTimer function. The full version of 14.3, available on the Web site, gives you the ability to experiment with the timer of your choice in conjunction with a completion routine or wait for a timer descriptor to signalize, resulting in four different combinations.
The last parameter, fResume, is related to power saving modes. For more information on this subject, refer to the help documentation.
The CancelWaitableTimer function is used to cancel the action of the previously called SetWaitableTimer function, but does not change the signal state of the timer. To do this, you need to call the SetWaitableTimer function again.
Example: using a wait timer
Program 14.3 demonstrates the use of a wait timer to generate periodic signals.
Program 14.3. TimeBeep: Generate periodic signals/ * Chapter 14. TimeBeep, p. Periodic sound notification. * /
/ * Usage: TimeBeep period (in milliseconds). * /
static BOOL WINAPI Handler (DWORD CntrlEvent);
static VOID APIENTRY Beeper (LPVOID, DWORD, DWORD);
volatile static BOOL Exit = FALSE;
int _tmain (int argc, LPTSTR argv) (
/ * Intercept keystrokesto terminate the operation. See chapter 4. * /
SetConsoleCtrlHandler (Handler, TRUE);
DueTime.QuadPart = - (LONGLONG) Period * 10000;
/ * The DueTime parameter is negative for the first timeout period and is set relative to the current time. The wait period is measured in ms (10 -3 s) and the DueTime is in units of 100 ns (10 -7 s) to match the FILETIME type. * /
hTimer = CreateWaitableTimer (NULL, FALSE / * "Sync Timer" * /, NULL);
SetWaitableTimer (hTimer, & DueTime, Period, Beeper, & Count, TRUE);
_tprintf (_T ("Count =% d \ n"), Count);
/ * The counter is incremented in the timer routine. * /
/ * Enter the standby state. * /
_tprintf (_T ("Completion. Counter =% d"), Count);
static VOID APIENTRY Beeper (LPVOID lpCount, DWORD dwTimerLowValue, DWORD dwTimerHighValue) (
* (LPDWORD) lpCount = * (LPDWORD) lpCount + 1;
_tprintf (_T ("Signal generation number:% d \ n"), * (LPDWORD) lpCount);
Fan (1000 / * Frequency. * /, 250 / * Duration (ms). * /);
BOOL WINAPI Handler (DWORD CntrlEvent) (
_tprintf (_T ("Shutdown \ n"));
An application programmer doesn't have to think about things like the way it works system programs with device registers. The system hides the details of low-level work with devices from applications. However, the distinction between polling and interrupt I / O is reflected to some extent at the level of system functions, in the form of functions for synchronous and asynchronous I / O.
Function execution synchronous input / output involves starting an I / O operation and waiting for the operation to complete. Only after I / O is complete does the function return control to the calling program.
Synchronous I / O is the most familiar way for programmers to work with devices. The standard I / O routines of programming languages work this way.
Function call asynchronous I / O means only the start of the corresponding operation. After that, the function immediately returns control to the calling program, without waiting for the operation to complete.
Consider, for example, asynchronous data entry. It is clear that the program cannot access the data until it is certain that its input is complete. But it is quite possible that the program can do other work for the time being, and not idle waiting.
Sooner or later, the program still has to start working with the entered data, but first make sure that the asynchronous operation has already completed. For this, various operating systems provide tools that can be divided into three groups.
· Waiting for the completion of the operation. It's like the "second half of a synchronous operation." The program first started the operation, then performed some extraneous actions, and now it waits for the end of the operation, as with synchronous I / O.
· Checking the completion of the operation. In this case, the program does not wait, but only checks the status of the asynchronous operation. If the I / O is not yet complete, then the program has the opportunity to walk for some time.
· Purpose of the completion procedure. In this case, by starting an asynchronous operation, the user program indicates to the system the address of the user procedure or function that should be called by the system after the operation completes. The program itself may no longer be interested in the I / O progress; the system will remind it of this at the right time by calling the specified function. This method is the most flexible, since the user can provide any actions in the termination procedure.
In a Windows application, all three methods are available for completing asynchronous operations. UNIX does not provide asynchronous I / O functions, but the same effect of asynchrony can be achieved differently by starting an additional process.
Asynchronous I / O execution can in some cases improve performance and provide additional functionality... Without such simplest form asynchronous input such as "no-wait keyboard input" would be impossible for numerous computer games and simulators. At the same time, the logic of a program using asynchronous operations is more complex than that of synchronous operations.
And what is the relationship mentioned above between synchronous / asynchronous operations and the methods of organizing I / O discussed in the previous paragraph? Answer this question yourself.
Data input / output
Most of the previous articles have been devoted to optimizing computational performance. We've seen many examples of tuning garbage collection, loop parallelization and recursive algorithms, and even tweaked the algorithms to reduce run-time overhead.
For some applications, optimization of the computational aspects provides only marginal performance gains because the bottleneck is I / O operations such as network transfers or disk access. From our experience, we can say that a significant proportion of performance problems are not related to the use of suboptimal algorithms or excessive load on the processor, but to inefficient use of input / output devices. Let's look at two situations where I / O optimization can improve overall performance:
An application can experience severe computational overhead due to inefficient I / O operations that add overhead. Worse, the congestion can be so great that it is a limiting factor in making the most of the I / O bandwidth.
An I / O device may not be fully utilized or its capabilities may be wasted due to inefficient programming patterns, such as transferring large amounts of data in small chunks or not using all the bandwidth.
This article describes general I / O concepts and provides recommendations for improving the performance of any type of I / O. These guidelines apply equally to network applications, disk-intensive processes, and even programs accessing non-standard, high-performance hardware devices.
Synchronous and asynchronous I / O
When executed in synchronous mode, Win32 API I / O functions (such as ReadFile, WriteFile, or DeviceloControl) block program execution until the operation completes. Although this model is very easy to use, it is not very effective. In the intervals between the execution of successive I / O requests, the device may be idle, that is, not fully used.
Another problem with synchronous mode is that the thread is wasting time on any concurrent I / O operation. For example, in a server application serving multiple clients at the same time, you might want to create a separate thread of execution for each session. These threads, which are idle most of the time, waste memory and can create situations thread thrashing when multiple threads of execution concurrently resume work after I / O completes and begin to struggle for processor time, resulting in increased context switches per unit time and reduced scalability.
The Windows I / O subsystem (including device drivers) internally operates in asynchronous mode — a program can continue to execute concurrently with an I / O operation. Almost all modern hardware devices are of an asynchronous nature and do not need to be constantly polled to transfer data or determine when an I / O operation is complete.
Most devices support the ability Direct Memory Access (DMA) to transfer data between the device and the computer's RAM without requiring the participation of the processor in the operation, and generate an interrupt upon completion of the data transfer. Synchronous I / O, which is internally asynchronous, is only supported at the Windows application layer.
In Win32, asynchronous I / O is called overlapped I / O, a comparison of synchronous and overlapping I / O modes is shown in the figure below:
When an application makes an asynchronous request for an I / O operation, Windows either performs the operation immediately or returns a status code indicating that the operation is pending. After that, the thread of execution can start other I / O operations or perform some calculations. The programmer has several ways to organize the reception of notifications about the completion of I / O operations:
Win32 Event: An operation awaiting this event will be performed upon completion of I / O.
Calling a custom function using a mechanism Asynchronous Procedure Call (APC): the thread must be in an alertable wait state.
Receiving notifications through I / O Completion Ports (IOCP): this is usually the most efficient mechanism. We will explore it in detail below.
Certain I / O devices (for example, a file opened in unbuffered mode) can provide additional benefits if the application is able to maintain a small number of pending I / O requests at all times. To do this, it is recommended that you first make several requests for I / O operations and make a new request for each executed request. This will ensure that the next operation is initiated by the device driver as soon as possible, without waiting for the application to complete the next request. But do not overdo it with the amount of data transferred, as this will consume limited kernel memory resources.
I / O completion ports
Windows supports an efficient asynchronous I / O completion notification mechanism called I / O Completion Ports (IOCP). In .NET applications, it is available through the method ThreadPool.BindHandle ()... This mechanism is used by internal implementations of some types in .NET that perform I / O operations: FileStream, Socket, SerialPort, HttpListener, PipeStream, and some .NET Remoting pipes.
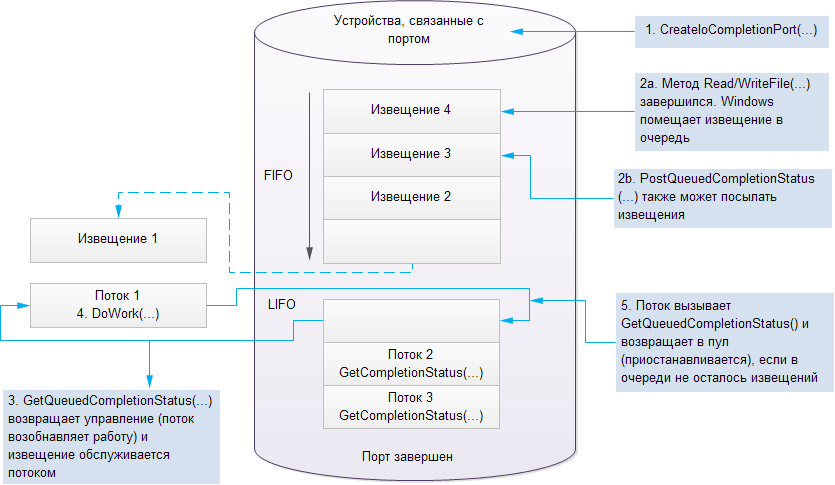
The IOCP mechanism shown in the figure above binds to multiple I / O descriptors (sockets, files, and specialized device driver objects) open asynchronously and to a specific thread of execution. As soon as the I / O operation associated with such a handle completes, Windows will add an alert to the appropriate IOCP port and pass the associated thread of execution for processing.
Using a pool of notifications and resuming threads that have initiated asynchronous I / O reduces the number of context switches per unit of time and increases processor utilization. Unsurprisingly, high-performance servers like Microsoft SQL Server use I / O completion ports.
Completion port is created by calling Win32 API function CreateIoCompletionPort that is passed the maximum concurrency value (number of threads), the completion key, and an optional handle to the I / O object. The termination key is a user-defined value that identifies various I / O descriptors. You can bind multiple handles to the same IOCP port by calling CreateIoCompletionPort again and passing in a handle to the existing completion port.
To establish communication with the specified IOCP port, user threads call the function GetCompletionStatus and await its completion. At any given time, a thread of execution can only be associated with one IOCP port.
Function call GetQueuedCompletionStatus blocks execution of the thread until it is notified (or the time-out), and then returns information about the completed I / O operation, such as the number of bytes transferred, the completion key, and the structure of the asynchronous I / O operation. If at the moment of the notification all the threads associated with the I / O port are busy (that is, there are no threads waiting in the GetQueuedCompletionStatus call), the IOCP engine will create a new thread of execution, up to the maximum concurrency value. If the thread has called GetQueuedCompletionStatus and the notification queue is not empty, the function will return immediately without blocking the thread in the operating system kernel.
The IOCP engine is able to determine that some of the "busy" threads are actually performing synchronous I / O, and start an additional thread, possibly exceeding the maximum parallelism value. Notifications can also be sent manually, without performing I / O, by calling the function PostQueuedCompletionStatus.
The following code demonstrates an example of using ThreadPool.BindHandle () with a Win32 file descriptor:
Using System; using System.Threading; using Microsoft.Win32.SafeHandles; using System.Runtime.InteropServices; public class Extensions (internal static extern SafeFileHandle CreateFile (string lpFileName, EFileAccess dwDesiredAccess, EFileShare dwShareMode, IntPtr lpSecurityAttributes, ECreationDisposition dwCreationDisposition, EFileAttributes dwFlagsAndAttributes, IntPtr hTemplateFile); static unsafe extern bool WriteFile (SafeFileHandle hFile, byte lpBuffer, uint nNumberOfBytesToWrite, out uint lpNumberOfBytesWritten , System.Threading.NativeOverlapped * lpOverlapped); enum EFileShare: uint (None = 0x00000000, Read = 0x00000001, Write = 0x00000002, Delete = 0x00000004) enum ECreationDisposition: uint (New = 1, CreateAlways = 2, OpenExisting = 3, OpenAlways 4, TruncateExisting = 5) enum EFileAttributes: uint (// ... Some flags are not shown Normal = 0x00000080, Overlapped = 0x40000000, NoBuffering = 0x20000000,) enum EFileAccess: uint (// ... Some flags are not shown GenericRead = 0x80000000 , GenericWrite = 0x40000000,) static lo ng _numBytesWritten; // Brake for the write stream static AutoResetEvent _waterMarkFullEvent; static int _pendingIosCount; const int MaxPendingIos = 10; // Completion routine, called by I / O streams static unsafe void WriteComplete (uint errorCode, uint numBytes, NativeOverlapped * pOVERLAP) (_numBytesWritten + = numBytes; Overlapped ovl = Overlapped.Unpack (pOVERLAP); Notify the write stream that the number of pending I / O operations has decreased // to the allowed limit if (Interlocked.Decrement (ref _pendingIosCount) = MaxPendingIos) (_waterMarkFullEvent.WaitOne ();)))))
Let's look at the TestIOCP method first. This is where the CreateFile () function is called, which is a P / Invoke function used to open or create a file or device. To perform I / O operations asynchronously, you must pass the EFileAttributes.Overlapped flag to the function. If successful, the CreateFile () function returns a Win32 file descriptor that we bind to the I / O completion port by calling ThreadPool.BindHandle (). Next, an event object is created that is used to temporarily block the thread that initiated the I / O operation if there are too many such operations (the limit is set by the MaxPendingIos constant).
Then a cycle of asynchronous write operations begins. Each iteration creates a buffer with data to write and Overlapped structure containing an offset within the file (in this example, writing is always done at offset 0), an event descriptor passed on completion of the operation (not used by the IOCP mechanism), and an optional custom object IAsyncResult which can be used to pass state to a completion function.
Next, the Overlapped.Pack () method is called, which accepts a completion function and a data buffer. It creates an equivalent low-level structure for the I / O operation by placing it in unmanaged memory and pinning the data buffer. Freeing unmanaged low-level memory and unpinning the buffer must be done manually.
If there aren't too many I / O operations going on at the same time, we call WriteFile () passing in the specified low-level structure. Otherwise, we wait until an event appears indicating that the number of pending operations is less than the upper limit.
The WriteComplete completion function is called by a thread from the I / O completion thread pool as soon as the operation is complete. It is passed a pointer to a low-level asynchronous I / O structure that can be unpacked and converted into a managed Overlapped structure.
In summary, when dealing with high performance I / O devices, use asynchronous I / O operations with completion ports, either directly by creating and using a custom completion port in an unmanaged library, or by linking Win32 handles to a completion port in .NET using ThreadPool.BindHandle () method.
Thread pool in .NET
A thread pool in .NET can be used successfully for a variety of purposes, and different types of threads are created to achieve each of them. While discussing parallel computing, we previously got acquainted with the thread pool API, where we used it to parallelize computational tasks. However, thread pools can also be used to solve problems of a different kind:
Worker threads can handle asynchronous calls to custom delegates (such as BeginInvoke or ThreadPool.QueueUserWorkItem).
I / O completion threads can service notifications from the IOCP global port.
Wait threads can wait for registered events to occur, allowing you to wait for several events at once in one thread (using WaitForMultipleObjects), up to the Windows upper limit (maximum wait objects = 64). The event listener is used to provide asynchronous I / O without using completion ports.
Timer threads waiting for multiple timers to expire.
Gate threads control the processor utilization by threads from the pool, and also change the number of threads (within the established limits) to achieve the highest performance.
It is possible to initiate I / O operations that appear to be asynchronous but are not. For example, calling the ThreadPool.QueueUserWorkItem delegate and then performing a synchronous I / O operation is not a truly asynchronous operation and is no better than performing the same operation on a normal thread.
Memory copy
It is not uncommon for a physical I / O device to return a buffer of data, which is copied over and over again until the application finishes processing it. Copying like this can take up a significant proportion of the processing power of the processor and should be avoided to maximize throughput. Next, we will look at a few situations where it is customary to copy data, and get acquainted with the techniques to avoid this.
Unmanaged memory
Working with a buffer located in unmanaged memory is much more difficult in .NET than with a managed byte array, so programmers, in search of the simplest way, often copy the buffer into managed memory.
If the functions or libraries you are using allow you to explicitly specify the buffer in memory or pass your callback function to allocate the buffer, allocate the managed buffer and pin it in memory so that it can be accessed by both a pointer and a managed reference. If the buffer is large enough (> 85,000 bytes), it will be created at Large Object Heap so try to reuse existing buffers. If reusing a buffer is complicated by the uncertainty of the object's lifetime, use memory pools.
In other cases, when functions or libraries themselves allocate memory (unmanaged) for buffers, you can access that memory directly by pointer (from unsafe code) or using wrapper classes such as UnmanagedMemoryStream and UnmanagedMemoryAccessor... However, if you need to pass a buffer to some code that only operates on byte arrays or string objects, copying may be inevitable.
Even if you cannot avoid copying memory and some or most of your data is filtered early, you can avoid unnecessary copying by checking if the data is needed before copying it.
Exporting part of a buffer
Programmers sometimes assume that byte arrays contain only the data they need, from start to finish, forcing the calling code to split the buffer (allocate memory for the new byte array and copy only the data it needs). This situation can often be seen in protocol stack implementations. In contrast, equivalent unmanaged code can take a simple pointer, not even knowing whether it points to the beginning of the actual buffer or to its middle, and a buffer length parameter to determine where the end of the data being processed is.
To avoid unnecessary memory copying, arrange for offset and length wherever you take a byte parameter. Use the length parameter instead of the Length property of the array, and add the offset value to the current indices.
Random read and merge write
Scatter Read and Merge Write is a Windows feature that reads or writes non-contiguous regions as if they were occupying a contiguous chunk of memory. This functionality in the Win32 API is provided in the form of functions ReadFileScatter and WriteFileGather... The Windows Sockets Library also supports the ability to read and write and write merge, providing its own functions: WSASend, WSARecv, and others.
Random read and merge write can be useful in the following situations:
When each packet has a fixed size header preceding the actual data. Scatter read and merge write can help you avoid having to copy headers whenever you want to get a contiguous buffer.
When you want to get rid of unnecessary system call overhead when doing I / O with multiple buffers.
Compared to the ReadFileScatter and WriteFileGather functions, which require each buffer to be exactly the size of one page, and the handle to be opened in asynchronous and unbuffered mode (which is an even bigger limitation), the socket-based read and write merge and scatter functions seem to be more practical. because they do not have these restrictions. .NET Framework Supports Bulb Read and Merge Writing for Sockets through Overloaded Methods Socket.Send () and Socket.Receive () without exporting generic read / write functions.
An example of using the read scatter and merge write functions can be found in the HttpWebRequest class. It concatenates the HTTP headers with the actual data without having to create a continuous buffer to store it.
File I / O
Usually file I / O is done through the cache file system, which provides some performance benefits: caching recently used data, read-ahead (pre-reading data from disk), lazy write (asynchronous write to disk), and concatenation of write operations for small chunks of data. By prompting Windows for the expected file access pattern, you can get additional performance gains. If your application is doing asynchronous I / O and is capable of addressing some of the buffering issues, then skipping the caching mechanism altogether may be a more efficient solution.
Caching management
When creating or opening files, programmers pass flags and attributes to the CreateFile function, some of which affect the behavior of the caching mechanism:
Flag FILE_FLAG_SEQUENTIAL_SCAN indicates that the file will be accessed sequentially, possibly skipping some parts, and random access is unlikely. As a result, the cache manager will look ahead and look beyond normal.
Flag FILE_FLAG_RANDOM_ACCESS indicates that the file will be accessed in no particular order. In this case, the cache manager will perform slightly ahead of the read, because of the reduced likelihood that the data read ahead will actually be required by the application.
Flag FILE_ATTRIBUTE_TEMPORARY indicates that the file is temporary, so the actual write operations to the physical medium (to prevent data loss) can be deferred.
In NET, these options are supported (except for the last one) by using the FileStream overloaded constructor that takes a parameter of the FileOptions enumeration type.
Random access has a negative impact on performance, especially when working with disk devices, as it requires moving heads. As technology advances, disk throughput has increased only by increasing storage density, not by decreasing latency. Modern disks are capable of reordering random access queries to reduce the overall time spent moving heads. This technique is called hardware command queuing (Native Command Queuing, NCO)... For this technique to be more effective, the disk controller needs to send several I / O requests at once. In other words, if possible, try to have multiple pending asynchronous I / O requests at once.
Unbuffered I / O
Unbuffered I / O operations are always performed without involving the cache. This approach has advantages and disadvantages. As with the cache control technique, unbuffered I / O is enabled through the "flags and attributes" parameter during file creation, but .NET does not provide access to this feature.
Flag FILE_FLAG_NO_BUFFERING disables caching for read and write operations, but does not affect the caching performed by the disk controller. This avoids copying (from the user's buffer to the cache) and "pollution" of the cache (filling the cache with unnecessary data and displacing the necessary ones). However, unbuffered reads and writes must adhere to alignment requirements.
The following parameters must be equal to or multiples of the disk sector size: single transfer size, file offset, and memory buffer address. Typically, a disk sector is 512 bytes in size. The latest high-capacity disk drives have a sector size of 4096 bytes, but they can operate in compatibility mode by emulating 512-byte sectors (at the expense of performance).
Flag FILE_FLAG_WRITE_THROUGH instructs the cache manager to immediately flush writeable data from the cache (unless the FILE_FLAG_NO_BUFFERING flag is set) and tells the disk controller to write to the physical media immediately without storing the data in the intermediate hardware cache.
Read-ahead improves performance by utilizing more disk space, even when the application is reading synchronously with delays between operations. The correct definition of which part of the file an application asks for next is Windows-dependent. By disabling buffering, you also disable read-ahead, and must keep the disk device busy by performing multiple overlapping I / O operations.
Latency writes also improve the performance of applications that perform synchronous writes by giving the illusion that disk writes are very fast. The app will be able to improve CPU usage by blocking for shorter intervals. With buffering disabled, the write operations will take the full amount of time it takes to finish writing data to disk. Therefore, using asynchronous I / O with buffering disabled becomes even more important.